速览目录 · 全部 21 篇
| # | 论文 | 领域 | Votes | 一句话 |
|---|---|---|---|---|
| 1 | HACRL | 多Agent RL | 133 | 异构Agent共享验证rollout实现双向互学,AIME准确率+21% |
| 2 | Helios | 视频生成 | 119 | 14B模型单H100实现19.5FPS实时长视频生成 |
| 3 | T2S-Bench & SoT | 推理/提示 | 102 | 结构化思维提示+首个文本到结构评测基准 |
| 4 | Proact-VL | 实时交互 | 24 | 主动式VideoLLM用于实时游戏AI伴侣 |
| 5 | MemSifter | Agent记忆 | 23 | 小模型代理推理卸载LLM长期记忆检索 |
| 6 | ArtHOI | 人体交互 | 19 | 从视频先验4D重建合成铰接物体人机交互 |
| 7 | Phi-4-reasoning-vision | 多模态推理 | 13 | 微软15B开源多模态推理模型,数学科学见长 |
| 8 | Memex(RL) | Agent记忆 | 11 | 索引式经验记忆+RL优化扩展长horizon Agent |
| 9 | CubeComposer | 360°视频 | 10 | 立方体分解+时空自回归原生4K 360°视频生成 |
| 10 | V₁ | 推理验证 | 10 | 统一生成与配对自验证,Pass@1提升最高10% |
| 11 | AgilePruner | 模型压缩 | 6 | 注意力+多样性自适应视觉Token剪枝 |
| 12 | InfinityStory | 视频生成 | 5 | 无限长视频生成:世界一致性+角色感知 |
| 13 | RIVER | 视频评测 | 4 | 视频LLM实时交互评测基准 |
| 14 | SWE-CI | Coding Agent | 3 | 持续集成场景下的代码Agent维护评测 |
| 15 | MUSE | 安全评测 | 2 | 多模态统一安全评估运行平台 |
| 16 | Specificity-aware RL | 细粒度分类 | 2 | 针对开放世界细粒度分类的特异性感知RL |
| 17 | EmbodiedSplat | 3D理解 | 1 | 在线前馈语义3DGS的开放词汇3D场景理解 |
| 18 | BeamPERL | 参数高效RL | 1 | 可验证奖励+参数高效RL让小模型专精代码 |
| 19 | MIBURI | 手势合成 | 1 | 面向表达性交互手势合成 |
| 20 | GroupEnsemble | 目标检测 | 1 | DETR不确定性估计的高效集成方法 |
| 21 | HDINO | 目标检测 | 0 | 简洁高效的开放词汇检测器 |
今天 21 篇论文,两条主线清晰:多Agent协同与强化学习的新范式——HACRL 提出异构Agent共享验证rollout的协同训练范式,133 票领跑,在 AIME 2025 上实现 +21% 准确率提升;MemSifter 和 Memex(RL) 分别从不同角度攻克 Agent 长期记忆难题。视频生成迈入实时+高分辨率时代——Helios 119 票紧随其后,14B 参数模型在单张 H100 上实现 19.5 FPS 实时长视频生成;CubeComposer 则首次实现原生 4K 360° 全景视频生成。
Insight:当 HACRL 让不同策略的 Agent 互相学习而非单向蒸馏,当 Helios 用架构创新绕过 KV-cache/稀疏注意力等加速技巧实现实时生成——AI 研究正从「单点突破」转向「系统性重设计」,不再满足于修补瓶颈,而是从底层范式上重构。
HACRL: 异构Agent协同强化学习——不同模型互相学习,AIME准确率+21%
当前的 LLM 强化学习主流方式是每个模型独立用自己的 on-policy rollout 训练,不同模型之间没有知识共享。传统多Agent RL(MARL)需要协调部署,知识蒸馏只能单向传递。HACRL(Heterogeneous Agent Collaborative RL)提出一种新范式:训练时协作,推理时独立——异构Agent在训练阶段共享经过验证的rollout数据,互相改进,推理时各自独立运行。
核心算法 HACPO(Heterogeneous Agent Collaborative Policy Optimization)的关键设计包括:(1) 双向rollout共享:不是传统的教师→学生单向传递,而是异构Agent之间双向互利——弱模型从强模型的正确rollout中学习,强模型也从弱模型的有效探索中获益;(2) 验证过滤:只共享通过正确性验证的rollout,避免噪声数据污染;(3) 原则性的off-policy修正:通过重要性采样比率剪裁,确保使用其他Agent生成的rollout时策略更新稳定。
实验在数学推理任务上验证:以 Qwen2.5-{7B, 32B} 作为异构Agent对,HACRL 在 AIME 2025 上将 7B 模型准确率从约 40% 提升至 61%(+21%),32B 模型也同时获益。HACRL 最大化了样本利用效率,特别是在 rollout 生成成本高昂的数学推理场景中,共享验证数据显著减少了冗余计算。
Helios: 14B参数单H100实现19.5FPS实时长视频生成
Helios 的标题用了「Real Real-Time」双重强调——它是首个在单张 NVIDIA H100 GPU 上实现 19.5 FPS 的 14B 参数视频生成模型,同时支持分钟级长视频生成,质量匹配强基线。三个关键突破让它区别于此前所有视频生成工作:
(1) 无需抗漂移技巧即可长视频稳定——不用 self-forcing、error-bank 或关键帧采样等常见启发式方法,Helios 依靠统一的输入表示和自回归扩散架构内在地保持时序一致性。(2) 无需标准加速技巧即可实时——不用 KV-cache、稀疏/线性注意力或量化,而是通过架构层面的重设计(统一输入表示 + 高效注意力机制)直接达到实时速度。(3) 训练无需并行/分片框架——在 80GB GPU 内存中可容纳最多四个 14B 模型,达到图像扩散模型级的 batch size。
Helios 采用自回归扩散模型架构,关键创新在于统一输入表示:将条件帧和生成帧统一到同一个表示空间,使得模型可以原生地处理任意长度的视频序列。在质量方面,Helios 匹配了远更慢的基线模型,同时生成速度快了一个数量级以上。这意味着交互式视频生成和实时视频编辑正在从理论走向实践。
T2S-Bench & Structure-of-Thought: 让模型先构建文本结构再答题,平均+5.7%提升
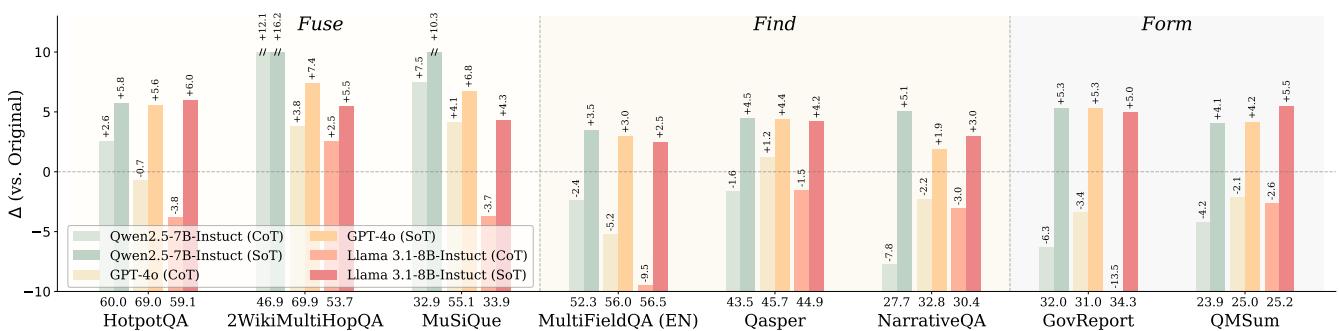
人类处理复杂阅读任务时,会标记要点、推断关系、组织结构。Structure of Thought (SoT) 将这一思路转化为提示技术:显式引导模型先构建中间文本结构(关键节点+关系链接),然后再生成最终答案。这不是 CoT 的变体——CoT 关注推理链条,SoT 关注信息结构化,让模型在回答前先「画出思维导图」。
配套的 T2S-Bench 是首个专门评估文本到结构能力的基准,包含 1.8K 样本,覆盖 6 个科学领域和 32 种结构类型。对 45 个主流模型的评测揭示了巨大的改进空间:多跳推理任务平均准确率仅 52.1%,最强模型也只有 58.1%。
在 Qwen2.5-7B-Instruct 上,SoT 单独使用在 8 个文本处理任务上带来平均 +5.7% 提升;在 T2S-Bench 上微调后增益进一步提升至 +8.6%。结果表明显式文本结构化是一个通用的中间表示(IR),可以系统性地增强模型在检索、融合、生成等多种文本处理任务上的表现。
Proact-VL: 主动式VideoLLM——让AI实时做游戏解说和引导

做一个好的 AI 游戏伴侣需要解决三个难题:(1) 在连续视频流下实现低延迟推理;(2) 自主判断何时该说话;(3) 控制内容质量和数量以满足实时约束——说太多会干扰体验,说太少又失去伴侣感。Proact-VL 正面攻克这三个问题,通过三大组件实现人类级的环境感知和交互。
框架设计包含:(1) Chunk-wise 输入输出:将视频流切分为固定长度的片段逐段处理;(2) 轻量主动响应机制:基于视觉和上下文线索自主决策何时回应;(3) 多层级损失函数:确保训练稳定性。配套构建了大规模 Live Gaming Benchmark,覆盖独立解说、多人联合解说、用户引导三种场景。
实验表明 Proact-VL 在 TimeDiff 和 F1 等指标上优于现有方法,说明它更好地对齐了人类解说模式。同时保持了通用视频理解能力不下降——这是「专精不牺牲通用」的典型案例。
MemSifter: 用小模型代理推理卸载LLM长期记忆检索
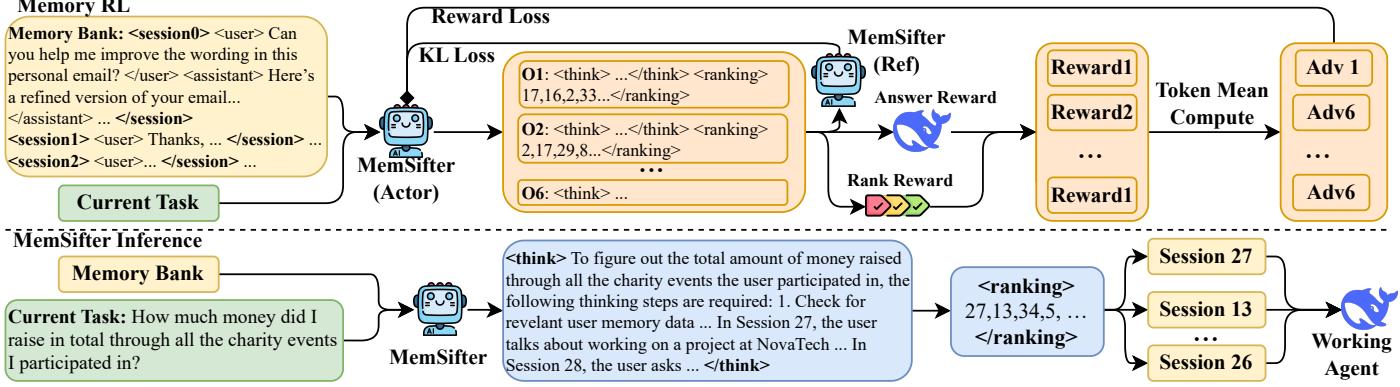
LLM 长期记忆面临一个根本性权衡:简单存储检索不准,复杂索引计算太重。Memory Graph 等结构化增强方法需要大量预处理(摘要、实体提取、图构建),而且大部分记忆永远不会被重用,前期索引成本基本浪费。让工作 LLM 自己读记忆又太贵——双重负担。
MemSifter 的核心思路是将记忆检索卸载给一个小规模代理模型。小模型先对任务进行推理,理解需要什么信息,然后检索必要的记忆。索引阶段零重计算,推理阶段仅增加最小开销。优化小模型使用了任务结果导向的强化学习:奖励基于工作 LLM 实际完成任务的表现,而非检索本身的精度——这确保检索到的是真正对任务有帮助的记忆。
在 8 个 LLM 记忆基准(包括 Deep Research 任务)上,MemSifter 在检索精度和最终任务完成度上达到或超过现有最优方法。模型权重、代码和训练数据均已开源。
ArtHOI: 从视频先验做4D重建——零样本合成铰接物体的人机交互
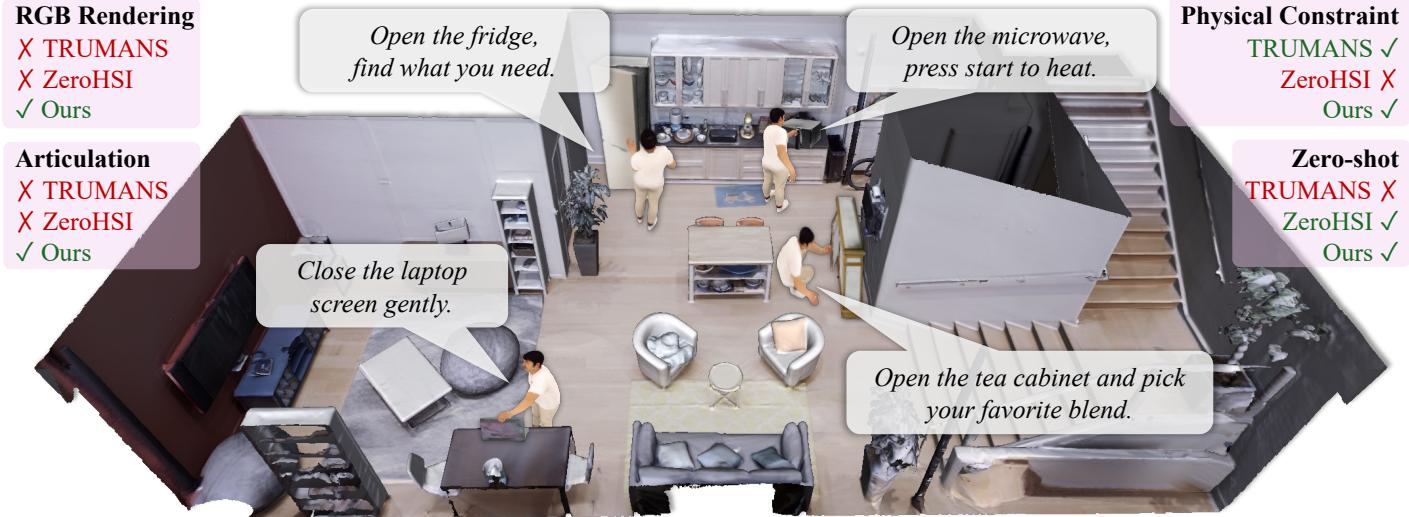
合成人与铰接物体(开冰箱、开柜门、开微波炉)的物理可信交互,在没有任何3D/4D监督的条件下极具挑战。现有零样本方法主要局限于刚性物体操作,无法建模铰接物体的部件级运动学约束。ArtHOI 将这个问题重新定义为从单目视频先验进行4D重建。
流程分两步:(1) 用视频扩散模型生成一段2D视频;(2) 将生成的视频作为监督信号,通过逆渲染重建几何一致且物理合理的4D场景。关键技术包括:基于光流的部件分割(用光流作为几何线索区分动态/静态区域)和解耦重建管线(先恢复物体铰接运动,再基于此合成人体动作,避免联合优化的单目歧义问题)。
在多种铰接场景上,ArtHOI 在接触精度、穿透减少和铰接保真度上均显著优于此前方法,将零样本交互合成从刚性操作扩展到了铰接物体领域。
Phi-4-reasoning-vision: 微软15B开源多模态推理模型,数据质量仍是最大杠杆
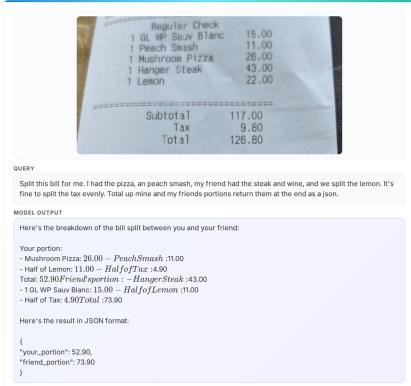
微软发布 Phi-4-reasoning-vision-15B,一个紧凑的开源多模态推理模型。定位清晰:通用视觉-语言任务表现良好,数学和科学推理以及UI理解能力出色。报告详细分享了设计动机、数据选择、架构消融和训练洞见——是一份面向社区的实践指南。
三个核心发现:(1) 数据质量仍是最大杠杆——系统性的过滤、纠错和合成增强带来的提升最为显著,远超架构层面的调整;(2) 高分辨率动态分辨率编码器带来一致提升——准确感知是高质量推理的前提;(3) 推理/非推理混合训练+模式标记让单一模型在简单任务上给出快速直接答案,在复杂任务上启动链式推理。
在计算效率-精度 Pareto 前沿上,Phi-4-reasoning-vision 以十分之一甚至更少的推理计算和 token 消耗达到了与远更大模型相竞争的精度,特别是在数学和科学推理上。
Memex(RL): 索引式经验记忆——Agent学会何时存、何时取、如何索引
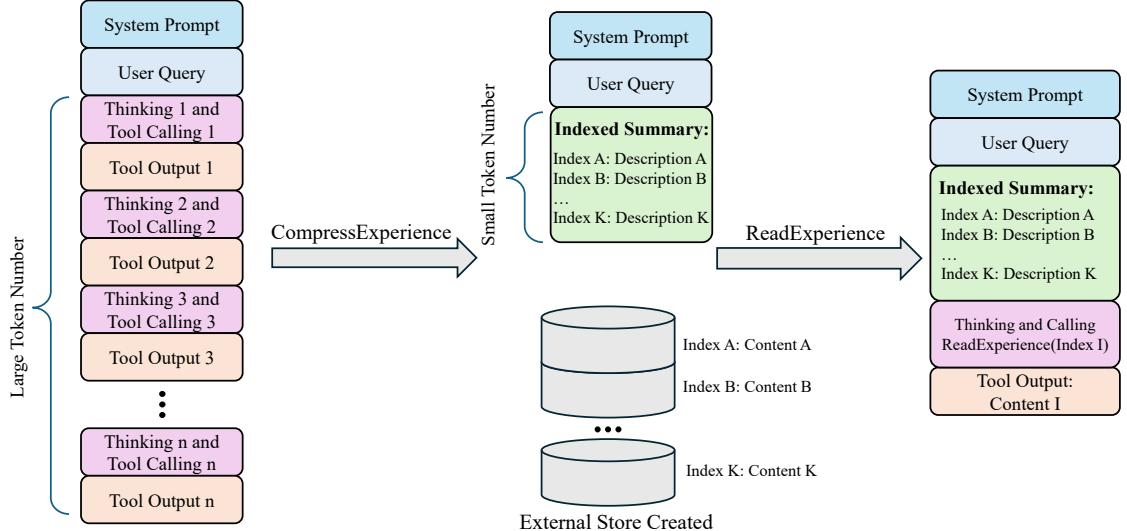
LLM Agent 在长horizon任务上被有限上下文窗口死死卡住。现有方案要么截断历史(有损),要么摘要压缩(丢失细节),要么全部塞外部记忆用相似性检索(在噪声片段海里捞针)。Memex 提出了一种索引式经验记忆机制:在紧凑的工作上下文中维护结构化摘要和稳定索引,完整的交互历史存储在外部数据库中。
核心创新在于 MemexRL:用强化学习训练 Agent 自己学会四件事——(1) 什么该摘要,(2) 什么该归档,(3) 如何建索引,(4) 何时解引用取回完整证据。奖励塑形专门针对有限上下文预算下的索引记忆使用进行优化。这样做的好处是压缩上下文但不丢弃证据——Agent 可以随时通过索引取回原始数据。
理论分析表明 Memex 循环在有限解引用次数下可保持决策质量,同时有效上下文计算量随历史增长保持有界。实验在长horizon任务上验证:Memex Agent 使用显著更小的工作上下文即可提升任务成功率。
CubeComposer: 立方体分解+时空自回归,首次实现原生4K 360°视频生成

VR 沉浸体验对 360° 全景视频的分辨率要求极高(原生 4K 即 3840×1920),但现有方法受限于标准扩散模型的全注意力计算,原生分辨率上限仅约 1K,只能通过后处理超分辨率勉强提升——外部上采样缺乏生成推理能力,高分辨率但细节缺失。
CubeComposer 的核心思路是立方体映射分解 + 时空自回归:将 360° 视频表示为六面立方体贴图,逐块生成而非一次性生成整个全景,从而大幅降低峰值内存。三项关键设计:(1) 时空自回归策略:精心规划的跨面+跨时间窗口生成顺序,确保一致性;(2) 立方体面上下文管理:稀疏上下文注意力提升效率;(3) 连续性感知技术:立方体感知位置编码、填充和混合,消除边界接缝。
在基准数据集上,CubeComposer 在原生分辨率和视觉质量上均超越现有方法,首次证明扩散模型可以原生生成 4K 360° 视频,为 VR 内容创作开辟了实用路径。
V₁: 统一生成与配对自验证,Pass@1提升最高10%
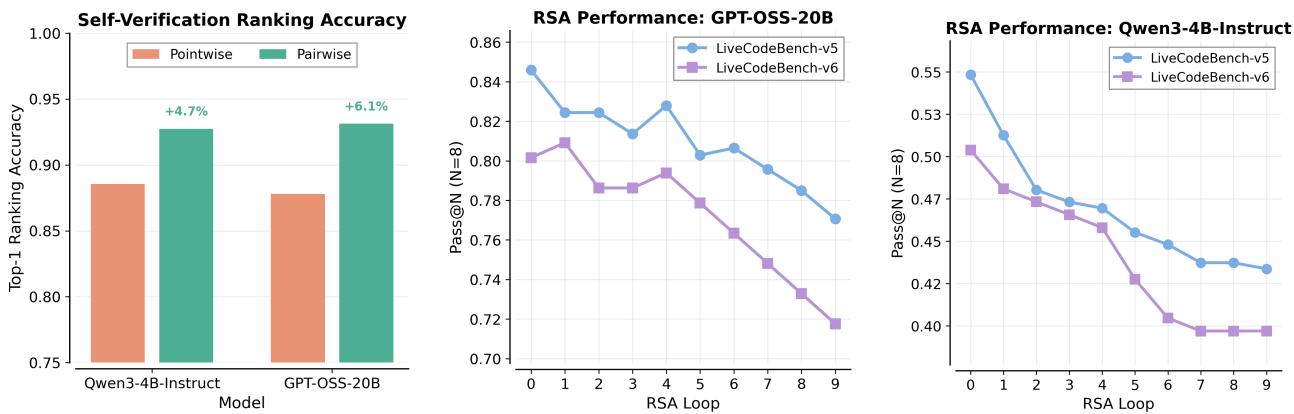
测试时扩展(test-time scaling)通过采样多个候选解并聚合来提升效果,但瓶颈在于验证:如何可靠地从候选集中识别正确解?现有方法通常独立打分每个候选,但实验发现模型在配对比较(pairwise comparison)时验证准确率远高于独立打分。
V₁ 包含两个组件:(1) V₁-Infer——不确定性引导的锦标赛排名算法,将有限的验证计算预算动态分配给相对正确性最不确定的候选对;(2) V₁-PairRL——联合训练单一模型同时作为生成器和配对自验证器,确保验证器适应生成器不断演化的分布。
在代码生成(LiveCodeBench、CodeContests、SWE-Bench)和数学推理(AIME、HMMT)基准上,V₁-Infer 的 Pass@1 比逐点验证提升最高 10%,且效率显著更高。V₁-PairRL 在测试时扩展增益上比标准 RL 提升 7-9%。
其余论文速览 · #11-21
| # | 论文 | 领域 | Votes | 一句话 |
|---|---|---|---|---|
| 11 | AgilePruner | 模型压缩 | 6 | 注意力+多样性自适应视觉Token剪枝实验研究 |
| 12 | InfinityStory | 视频生成 | 5 | 无限长视频生成:世界一致性+角色感知控制 |
| 13 | RIVER | 视频评测 | 4 | 视频LLM实时交互基准 |
| 14 | SWE-CI | Coding Agent | 3 | 持续集成场景下的代码Agent维护评测 |
| 15 | MUSE | 安全评测 | 2 | 多模态统一安全评估平台 |
| 16 | Specificity-aware RL | 细粒度分类 | 2 | 开放世界细粒度分类的特异性感知RL |
| 17 | EmbodiedSplat | 3D理解 | 1 | 在线前馈语义3DGS开放词汇场景理解 |
| 18 | BeamPERL | 参数高效RL | 1 | 可验证奖励+参数高效RL让小模型专精代码 |
| 19 | MIBURI | 手势合成 | 1 | 面向表达性交互手势合成 |
| 20 | GroupEnsemble | 目标检测 | 1 | DETR不确定性估计的高效集成方法 |
| 21 | HDINO | 目标检测 | 0 | 简洁高效的开放词汇检测器 |
今日趋势
- Agent 记忆双响:MemSifter(小模型代理检索)和 Memex(RL)(索引式经验记忆+RL)从不同路径攻克同一问题——LLM Agent 的长期记忆管理。两者都指向一个方向:让 Agent 自主学会记忆策略,而非依赖手工设计。
- 视频生成从「能生成」到「能实时」:Helios 的 19.5 FPS 和 CubeComposer 的原生 4K 360° 标志着视频生成正在突破速度和分辨率的双重瓶颈,交互式应用和 VR 内容创作的门槛大幅降低。
- 结构化思维超越链式推理:SoT 的 +5.7% 一致性提升表明,在 CoT(链式推理)之外,「先结构化再推理」是一个通用且被低估的增强维度。
参考来源
- HACRL — huggingface.co/papers/2603.02604
- Helios — huggingface.co/papers/2603.04379
- T2S-Bench & SoT — huggingface.co/papers/2603.03790
- Proact-VL — huggingface.co/papers/2603.03447
- MemSifter — huggingface.co/papers/2603.03379
- ArtHOI — huggingface.co/papers/2603.04338
- Phi-4-reasoning-vision — huggingface.co/papers/2603.03975
- Memex(RL) — huggingface.co/papers/2603.04257
- CubeComposer — huggingface.co/papers/2603.04291
- V₁ — huggingface.co/papers/2603.04304