速览 · Quick View
| # | 技术方向 | 论文数 | 代表作 | 关键指标 |
|---|---|---|---|---|
| 1 | 推理强化 | 218 (33.5%) | GSPO (317↑), rStar-Math (288↑) | 7B 模型超 o1 |
| 2 | 算法创新 | 112 (17.2%) | GSPO (317↑), GDPO (228↑) | GRPO 系改进 |
| 3 | 多模态 RL | 114 (17.5%) | Vision-Zero (140↑), Unified RM (123↑) | 视觉推理强化 |
| 4 | Agent RL | 99 (15.2%) | GLM-4.1V-Thinking (251↑), EPO (135↑) | Agent 策略优化 |
| 5 | 对齐与安全 | 48 (7.4%) | DAA Blur (113↑), Meta-Abilities (120↑) | DPO vs PPO 辩论 |
| 6 | 奖励建模 | 36 (5.5%) | Unified RM (123↑), PRM (152↑) | 过程/结果奖励 |
| 7 | 训练方法 | 23 (3.5%) | Reflect,Retry,Reward (277↑), ProRL (143↑) | 自我进化训练 |
| 8 | 理论分析 | 1 (0.2%) | — | 缩放定律 |
全景概述:从「对齐工具」到「推理引擎」
2024-2025 年,强化学习在大模型领域经历了一场根本性转变:从单纯的人类偏好对齐工具,蜕变为驱动深度推理能力的核心引擎。DeepSeek R1[1] 的成功证明了一个震撼性结论——纯 RL 训练可以激发 LLM 的深度推理能力,无需监督微调。这一发现引爆了 RL for Reasoning 的研究热潮,推理强化方向以 218 篇论文占据了全部 651 篇 RL 论文的 33.5%。
我们对这 651 篇论文进行了系统性梳理,识别出三条主线性的技术演进脉络:
从 RLHF 到 RLVR
强化学习的奖励信号从人类偏好转向可验证奖励(数学正确性、代码执行结果),大幅降低了奖励建模的成本和噪声。RLVR(Reinforcement Learning with Verifiable Rewards)正在成为新的主流范式,推动 RL 从对齐走向推理。
算法迭代加速
PPO → DPO → GRPO → GSPO → GDPO,每一代都在解决前一代的核心瓶颈:PPO 过于复杂、DPO 过于简单、GRPO 存在 Token 级噪声累积、多奖励场景需要解耦归一化。算法迭代周期从年级缩短到季度级。
小模型大能力
rStar-Math[3] 让 7B 模型在数学推理上超越 o1-preview,Absolute Zero[4] 实现零数据自我进化,VibeThinker-1.5B 用 1.5B 参数展现多样性驱动推理。RL 是小模型突破性能天花板的关键杠杆。
技术演进图:RL 算法的迭代加速
过去三年,大模型 RL 算法以前所未有的速度迭代。从 2023 年的 PPO/DPO 双雄对峙,到 2025 年 GRPO 系算法的百花齐放,再到 2026 年多奖励解耦和序列级优化的新范式——每一步都在解决前一代的核心瓶颈。
算法创新:GSPO 与 GDPO — GRPO 的两大继承者
GSPO: Group Sequence Policy Optimization
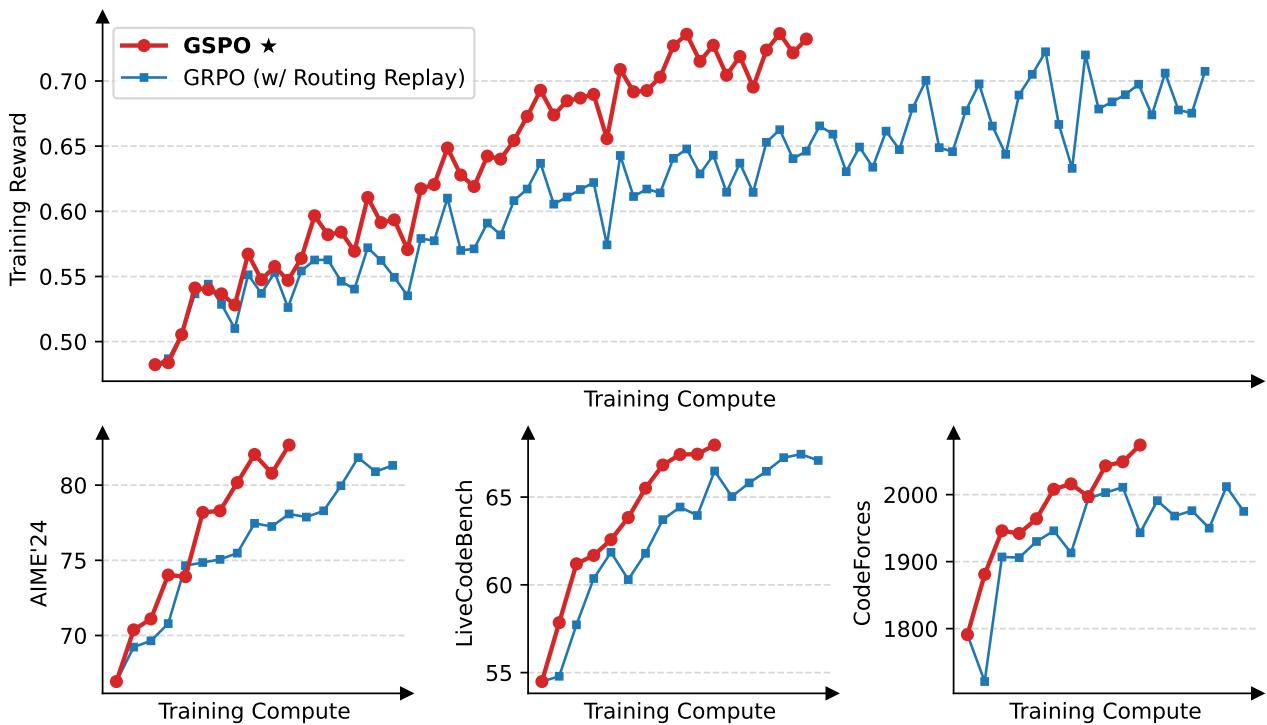
GSPO 发现了 GRPO 的一个根本性缺陷:Token 级重要性比率的噪声会在长序列中指数累积,导致训练不稳定。具体来说,GRPO 计算每个 Token 的 π(a|s)/πold(a|s) 并独立 Clipping,但当序列长度为 L 时,整体重要性比率是 L 个 Token 级比率的乘积——即使每个 Token 的偏差很小,累积效应也会导致序列级的巨大方差。
GSPO 的解决方案优雅而直接——将重要性比率从 Token 级提升到序列级,在序列级施加 Clipping。这一改动从数学上消除了噪声累积问题,特别是解决了 MoE(Mixture of Experts)模型的 RL 训练不稳定性难题。这是 Qwen3 系列模型的核心训练算法。实验证明 GSPO 在训练稳定性和最终性能上全面超越 GRPO,尤其在长序列推理任务上优势更加显著。
GDPO: Group Decomposed Policy Optimization
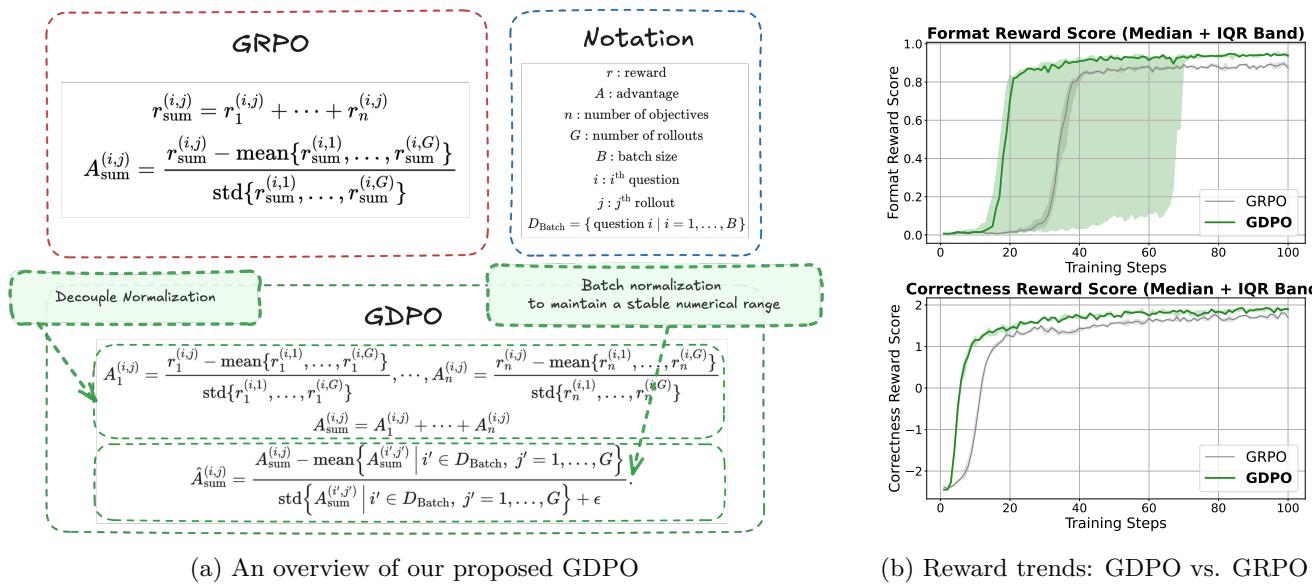
GDPO 解决了 GRPO 在多奖励场景下的优势塌缩(advantage collapse)问题。在实际训练中,模型往往同时接收多个奖励信号(如数学正确性、代码执行结果、格式规范性),这些奖励的量级差异巨大。GRPO 的组内归一化会让弱信号(如格式奖励)被强信号(如正确性奖励)淹没,导致模型只优化强信号而忽略弱信号。
GDPO 提出按奖励解耦归一化:每个奖励独立计算归一化优势值,然后加权组合。这确保了每个维度的奖励信号都能有效传播。在 DeepSeek-R1-1.5B 上的实验显示:工具调用准确率 +2.7%,AIME 数学推理 +6.3%。更重要的是,GDPO 在训练稳定性上也显著优于 GRPO,尤其在混合多种任务的训练中几乎不出现梯度爆炸。
算法对比:PPO → DPO → GRPO → GSPO → GDPO
| 算法 | 是否需要 RM | Token/Sequence 级 | 多奖励支持 | 训练稳定性 | 代表模型 |
|---|---|---|---|---|---|
| PPO | 需要 RM + Value Model | Token 级 | 加权求和 | 中等(需精细调参) | InstructGPT, ChatGPT |
| DPO | 不需要(隐式 RM) | 序列级 | 不支持 | 高(简单稳定) | Llama 2 Chat |
| GRPO | 不需要 Value Model | Token 级 | 组内归一化 | 中等(长序列噪声) | DeepSeek-Math/R1 |
| GSPO | 不需要 Value Model | 序列级 | 组内归一化 | 高(消除累积噪声) | Qwen3 系列 |
| GDPO | 不需要 Value Model | Token 级 | 解耦归一化 | 高(多奖励均衡) | NVIDIA 内部 |
推理强化:rStar-Math、Absolute Zero 与 RLVR 范式
rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking
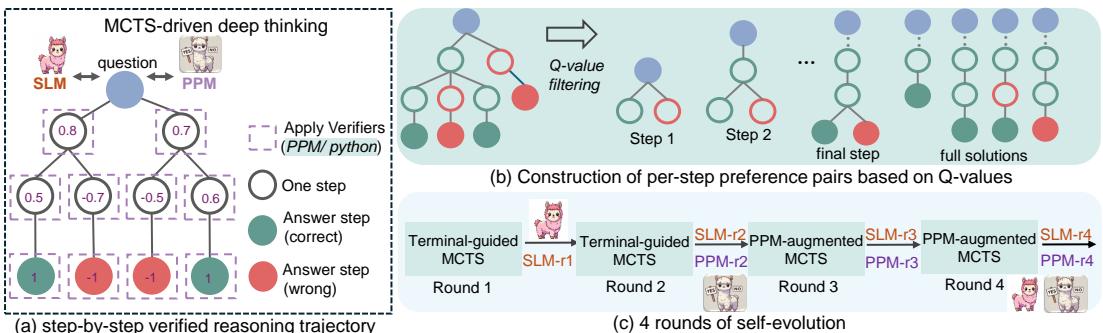
rStar-Math 证明了一个令人震撼的结论:7B 参数的小模型可以达到 OpenAI o1 级别的数学推理能力。核心方法是三重创新的结合——代码增强思维链(Code-augmented CoT)将数学推理步骤转化为可执行代码,使每一步都可以被自动验证;蒙特卡洛树搜索(MCTS)自我进化通过树搜索探索多条推理路径,自动生成高质量训练数据;过程偏好模型(PPM)基于树搜索的逐步验证提供过程级奖励信号,无需人工标注。
通过 4 轮自我进化迭代,Qwen2.5-Math-7B 在 MATH 基准上从 58.8% 提升到 90.0%,超过 OpenAI o1-preview 4.5 个百分点。关键洞察在于:传统的结果奖励(Outcome RM)只告诉模型「最终答案对不对」,而 PPM 提供了「每一步是否正确」的细粒度信号——这是小模型逆袭大模型的核心杠杆。
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
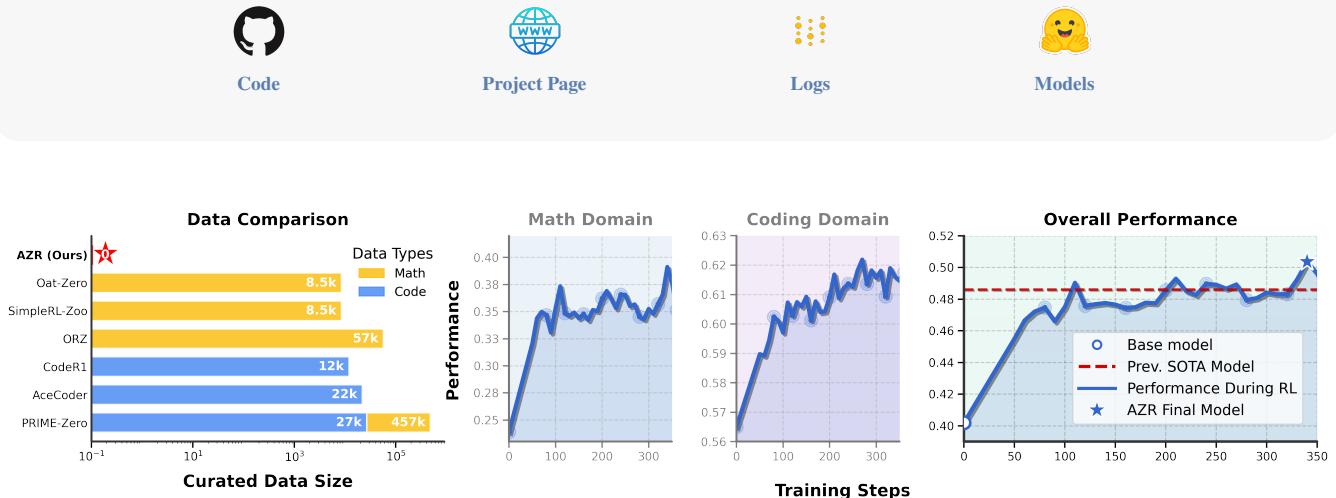
Absolute Zero 将自我进化推向极致:零外部数据。传统 RL 训练依赖人工标注的数据集(如数学题库),而 Absolute Zero 让单个模型同时扮演「出题者(Proposer)」和「解题者(Solver)」,通过自我对弈(self-play)持续进化。出题者学习生成「刚好够难」的问题——太简单模型学不到东西,太难模型无法求解——这种自适应难度调节是关键创新。
在编码和数学推理基准上,Absolute Zero 均达到 SOTA,超越使用数万条人工标注数据训练的模型 1.8 个绝对百分点。这意味着 RL 训练甚至可以摆脱对外部数据的依赖,仅依靠环境反馈(代码可执行、数学可验证)实现自主进化。
更多推理强化重要工作
Beyond 80/20 Rule 188↑
Qwen Team + 清华大学联合发现:RLVR 中仅约 20% 的高熵「分叉」Token 驱动了几乎全部性能提升。仅对高熵 Token 施加 RL 梯度即可达到甚至超越全 Token 训练效果。Qwen3-32B 在 AIME'24 达 63.5,AIME'25 达 56.7。[8]
DAPO 144↑
开源大规模 RL 系统,为 RLVR 研究提供了可复现的基础设施。系统性解决了大规模 RL 训练中的工程挑战,包括梯度累积、多节点同步和内存优化。[9]
Kimi k1.5 126↑
月之暗面的 RL 缩放实践报告,展示了 RL 训练从小规模到大规模的完整路径,包括长 CoT + 短 CoT 联合训练、Multi-task 多轮 RL 等工程经验。[10]
ProRL 143↑
提出延长 RL 训练以扩展推理边界的方法。发现当标准 RL 训练收敛后,通过调整学习率调度和奖励结构可以继续获得显著收益,将推理能力推向更远的边界。[11]
训练方法:Reflect, Retry, Reward 与 Beyond 80/20
Reflect, Retry, Reward: Self-Improving LLMs via Reinforcement Learning
这篇论文提出了一个优雅的三阶段 RL 框架,将 LLM 的自我改进过程分解为三个互补的步骤:反思(Reflect)——模型在得到错误答案后,生成对自身推理过程的语言分析,识别出具体的错误原因;重试(Retry)——基于反思结果,模型重新尝试解题,生成修正后的推理链;奖励(Reward)——对修正后的结果进行验证,正确则给予正奖励强化「反思 + 修正」的行为模式。
这一框架的核心洞察在于:仅强化最终答案的正确性是不够的——模型需要学会「从错误中学习」的元能力。传统 RL 只看最终结果对不对,而 Reflect-Retry-Reward 让模型先学会分析错误,再学会修正,最后通过奖励信号巩固整个自我改进回路。实验表明,经过该框架训练的模型在首次尝试失败后的修正成功率显著提升,且这种自我改进能力可以泛化到训练分布之外的新任务。
Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive RLVR
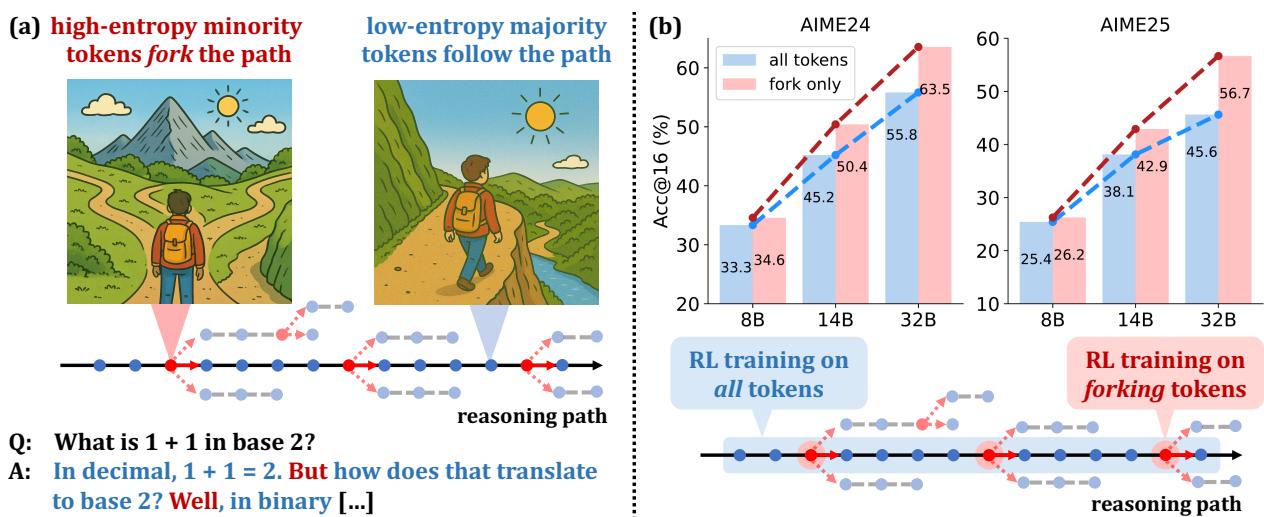
这篇论文揭示了 RLVR 训练的一个深层机制:并非所有 Token 对 RL 训练的贡献是均等的。通过对 RLVR 训练过程中每个 Token 的熵变化和梯度贡献进行精细分析,研究者发现仅约 20% 的高熵「分叉」Token(即模型在这些位置有多个高概率候选词的 Token)驱动了几乎全部的性能提升,其余 80% 的 Token 贡献微乎其微。
基于这一发现,论文提出了一种高效的选择性 RL 方法:仅对高熵 Token 施加 RL 梯度,跳过低熵(模型已经非常确定的)Token。这不仅大幅降低了计算成本,还避免了对已确定 Token 的无效梯度干扰。Qwen3-32B 在该方法下达到了 AIME'24 63.5、AIME'25 56.7 的成绩,是 600B 以下基座模型中的 RLVR SOTA。