2023 年 9 月,阿里通义实验室悄然在 HuggingFace 上线第一篇 Qwen 技术报告,彼时大多数人对这支团队的系统性野心尚无概念。两年多后的今天,26 篇论文、2905 个 Upvote 摆在面前,Qwen 家族已成为开源领域迭代速度最快、覆盖模态最全的模型体系之一。
纵观全局,Qwen 的演进有几条清晰主线:基座语言模型从 Qwen → Qwen2 → Qwen2.5 → Qwen3 四代迭代(Qwen3.5 已发布,arxiv 上暂无论文),每一代都在参数效率和多语言能力上显著跃升;多模态从视觉语言(Qwen-VL)→ 音频(Qwen-Audio)→ 全模态(Qwen3-Omni)持续扩展,直至在 36 个音视频基准中夺得 32 项开源 SOTA;能力边界则从语言模型延伸至代码生成、图像生成(Qwen-Image 系列)、嵌入检索(Qwen3 Embedding)以及安全护栏(Qwen3Guard)。
Insight:Qwen 是目前开源领域覆盖模态最全、迭代速度最快的模型家族。从 1.7B ASR 到 235B-A22B 全模态 MoE,通义实验室展示了一种"系统性铺张"的竞争策略——不求单点突破,而是以密集的产品线覆盖封堵竞争对手的市场缝隙。
📋 26 篇论文速览(时间倒序)
| # | 日期 | 论文 | 产品线 | Upvotes |
|---|---|---|---|---|
| 1 | 2026-01-30 | Qwen3-ASR | 语音识别 | ↑36 |
| 2 | 2026-01-23 | Qwen3-TTS | 语音合成 | ↑69 |
| 3 | 2026-01-16 | 安全评测报告 | 安全 | ↑25 |
| 4 | 2026-01-12 | Qwen3-VL-Embedding/Reranker | 多模态检索 | ↑56 |
| 5 | 2025-12-18 | Qwen-Image-Layered | 图像生成 | ↑66 |
| 6 | 2025-12-16 | QwenLong-L1.5 | 长上下文推理 | ↑108 |
| 7 | 2025-12-04 | Qwen3-VL | 视觉语言 | ↑159 |
| 8 | 2025-10-17 | Qwen3Guard | 安全护栏 | ↑15 |
| 9 | 2025-09-23 | Qwen3-Omni | 全模态 | ↑149 |
| 10 | 2025-08-05 | Qwen-Image | 图像生成 | ↑272 |
| 11 | 2025-06-06 | Qwen3 Embedding | 文本嵌入 | ↑79 |
| 12 | 2025-05-26 | QwenLong-L1 | 长上下文推理 | ↑88 |
| 13 | 2025-05-26 | QwenLong-CPRS | 上下文压缩 | ↑43 |
| 14 | 2025-05-19 | Qwen3 | 基座语言模型 | ↑337 |
| 15 | 2025-05-07 | Qwen3 量化研究 | 量化 | ↑25 |
| 16 | 2025-04-02 | Open-Qwen2VL | 多模态预训练 | ↑37 |
| 17 | 2025-03-27 | Qwen2.5-Omni | 全模态 | ↑170 |
| 18 | 2025-02-20 | Qwen2.5-VL | 视觉语言 | ↑214 |
| 19 | 2025-01-28 | Qwen2.5-1M | 长上下文 | ↑72 |
| 20 | 2024-12-20 | Qwen2.5 | 基座语言模型 | ↑377 |
| 21 | 2024-09-19 | Qwen2.5-Coder | 代码 | ↑153 |
| 22 | 2024-09-19 | Qwen2-VL | 视觉语言 | ↑78 |
| 23 | 2024-07-17 | Qwen2-Audio | 音频 | ↑64 |
| 24 | 2024-07-16 | Qwen2 | 基座语言模型 | ↑168 |
| 25 | 2023-11-15 | Qwen-Audio | 音频 | ↑10 |
| 26 | 2023-09 | Qwen | 基座语言模型 | ↑35 |
Qwen3-ASR:52 种语言、92ms 延迟,开源 SOTA 语音识别
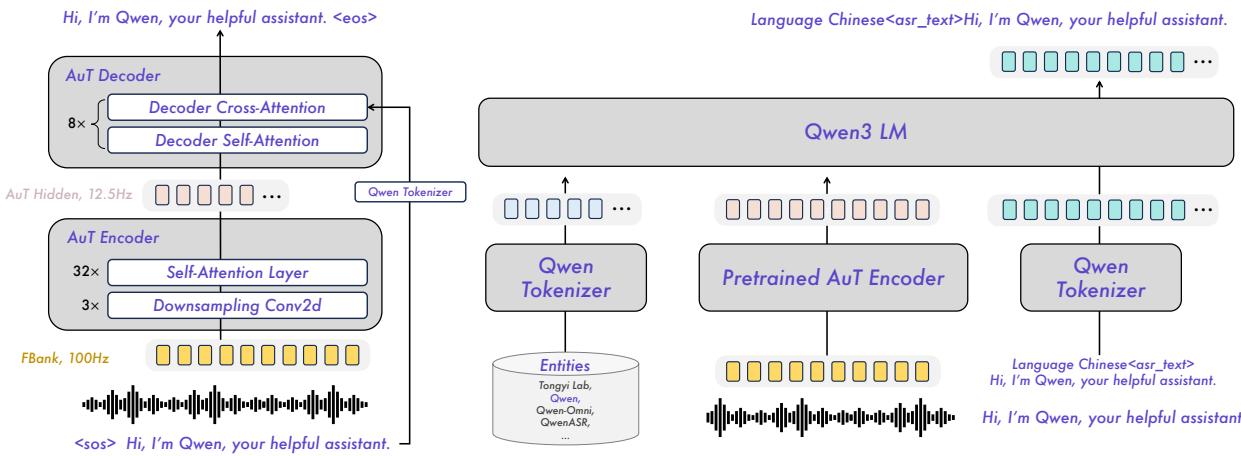
Qwen3-ASR 是通义实验室在 2026 年 1 月底推出的自动语音识别模型,同时发布 1.7B 和 0.6B 两个参数规模,支持多达 52 种语言与方言。该模型的核心能力直接继承自 Qwen3-Omni 的音频理解分支,并针对工业级 ASR 场景在推理效率和吞吐量上做了专项优化。
从架构角度看,Qwen3-ASR 采用端到端序列到序列设计,将 Qwen3-Omni 的音频编码器与优化后的解码器对齐,实现低延迟转录。0.6B 版本的 TTFT(首 Token 时延)低至 92ms,在 128 并发场景下单秒可转录 2000 秒语音,已达到工业级实时处理要求。
除核心 ASR 模型外,Qwen3-ASR 还随附 ForcedAligner-0.6B——一个非自回归(NAR)时间戳对齐模型,支持 11 种语言,可将转录文本与音频时间轴精确对齐,满足字幕生成、语音标注等下游任务需求。1.7B 版本在开源模型中达到 SOTA,与最强商业 ASR API 处于同等水平,并以 Apache 2.0 协议开源,是目前可商用的最强开源 ASR 选项之一。
在 CommonVoice、AISHELL、LibriSpeech 等多个多语言 ASR 基准上,Qwen3-ASR 1.7B 均超越同等参数量开源模型,并与 Whisper Large-v3、Azure STT 等商业方案持平甚至更优,验证了基于强大多模态底座的 ASR 蒸馏路线的可行性。
Qwen3-TTS:3 秒声音克隆、97ms 首包延迟,双分词器流式语音合成
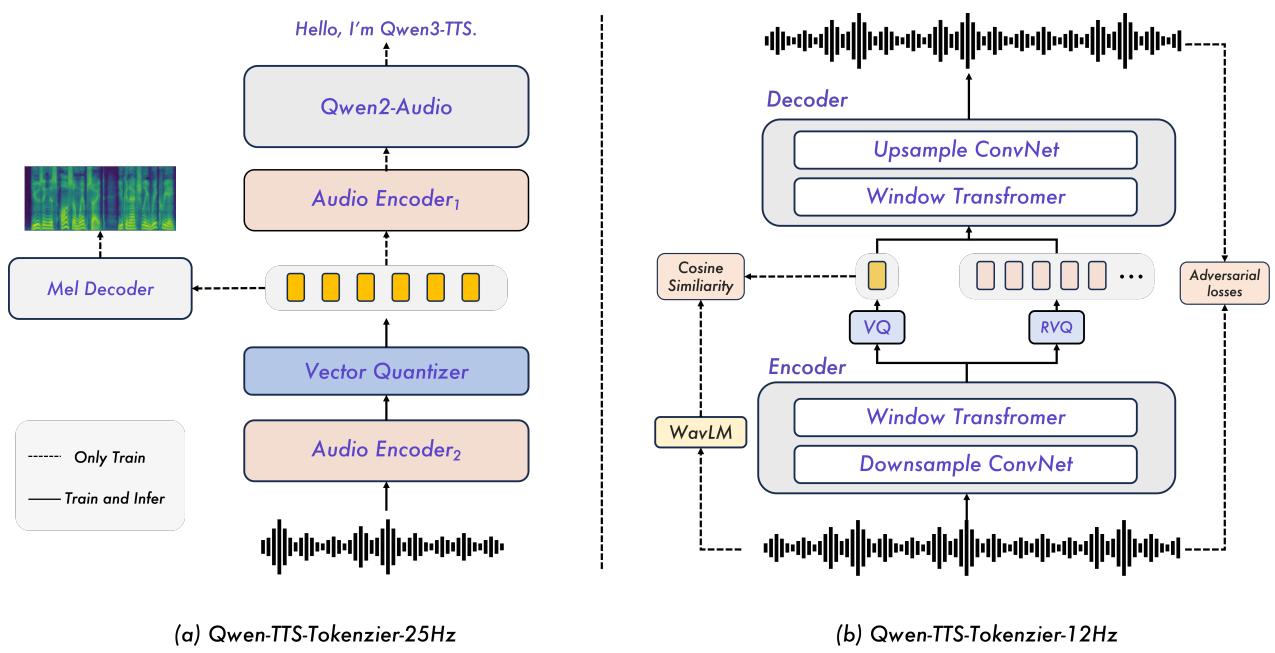
Qwen3-TTS 采用双轨语言模型(Dual-Track LM)架构,将语义理解与音频合成并行建模,实现真正意义上的实时流式语音生成。该模型训练数据涵盖 500 万小时多语言语音,支持 10 种语言,以 Apache 2.0 协议开源,是目前开源 TTS 中综合能力最强的方案之一。
架构创新集中在双分词器设计上:25Hz 分词器以语义保真为主,适合高质量离线合成;12.5Hz 分词器则将音频 token 压缩至极低码率,专为流式场景优化,首包延迟(TTFB)低至 97ms,满足实时交互场景要求。两套分词器可按场景灵活切换,兼顾音质与延迟。
在控制能力方面,Qwen3-TTS 支持仅需 3 秒参考音频的零样本声音克隆,同时允许通过自然语言描述控制音色、语调、语速等特征(描述控制),无需预定义说话人 ID。这一特性大幅降低了个性化 TTS 的门槛,在虚拟助手、有声书、配音自动化等场景有直接商业价值。
Qwen3-TTS 在 SEED-TTS-Eval、EvalSpeech 等多语言 TTS 基准上达到开源 SOTA,在英语、中文、日语、韩语等核心语言的主观 MOS 评分上与顶级商业 API 差距进一步缩小。
多模态大模型安全评测:GPT、Gemini、Qwen3-VL 等六大系统横评
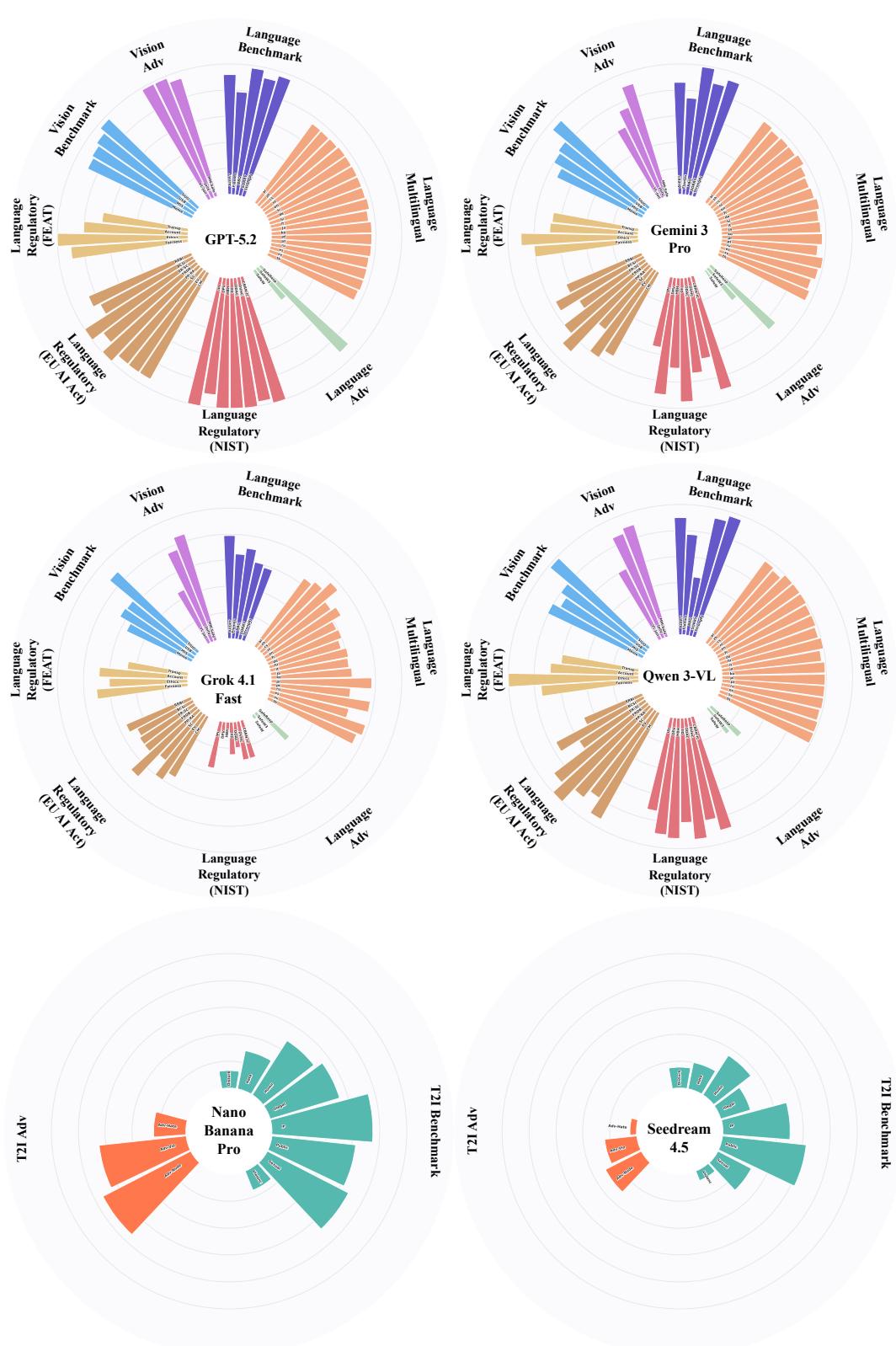
这篇安全评测报告由复旦大学研究团队发布,并非 Qwen 官方技术报告,但因其对 Qwen3-VL 进行了系统性评测而被纳入本盘点。报告在统一协议下对 6 个顶级多模态系统进行横向比较,覆盖 GPT-5.2、Gemini 3 Pro、Qwen3-VL、Doubao 1.8、Grok 4.1 Fast 和 Seedream 4.5。
评测框架设计是本报告最值得关注之处:四维评估体系——基准评测(标准化 benchmark)、对抗评测(红队攻击)、多语言评测(跨语言安全一致性)、合规评测(法规遵从),打破了以往单一维度安全评测的局限。同时,评测统一覆盖语言模态、视觉语言模态和图像生成模态,是目前最系统的多模态 AI 安全横评之一。
结果显示,Qwen3-VL 在多语言安全一致性和对抗场景下表现稳健,但各模型在不同评测维度上各有优劣,不存在全维度碾压的系统。报告的重要贡献在于为跨机构的多模态安全评测建立了可复现的标准协议,推动了该领域从"各自评测"走向"统一基准"。
Qwen3-VL-Embedding/Reranker:统一多模态表征空间,文档 / 图像 / 视频一体检索
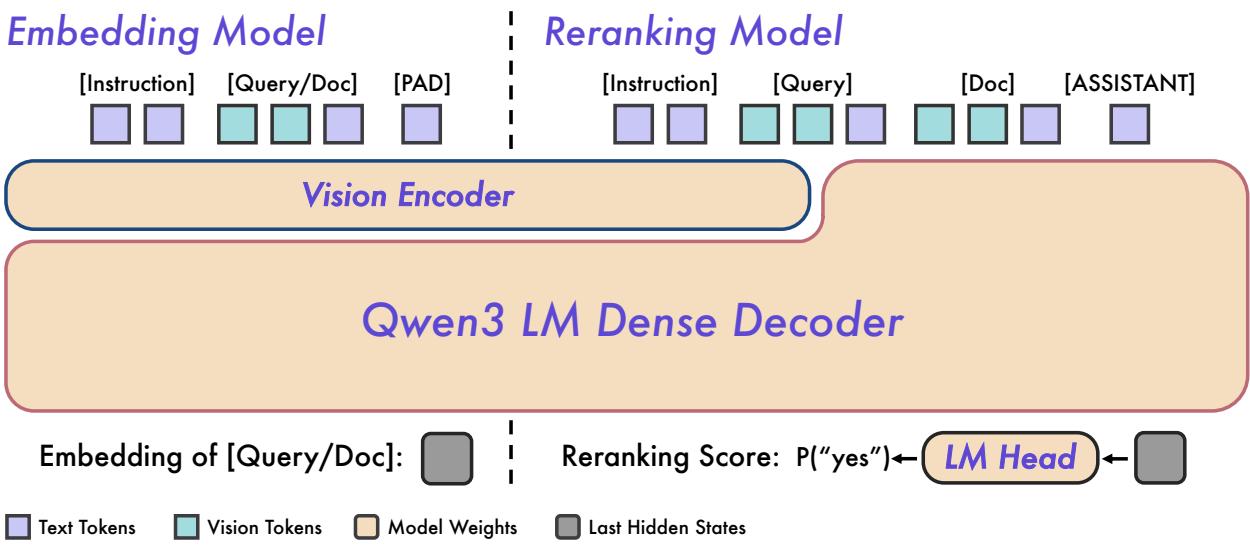
Qwen3-VL-Embedding/Reranker 是基于 Qwen3-VL 基础模型构建的多模态嵌入与重排序系列,核心目标是在统一向量空间中表征文本、自然图像、文档图像和视频帧,打破模态之间的检索壁垒。这是对 GTE-Qwen 系列在多模态维度的重大扩展。
训练管线采用多阶段策略:首先通过大规模对比预训练(Contrastive Pre-training)建立跨模态对齐的初始表征,再通过重排序蒸馏(Reranker Distillation)进一步提升检索精度。该模型还引入 Matryoshka 表征学习(MRL),允许用户根据存储和计算预算灵活选择嵌入维度,无需重新训练即可在不同精度-效率点间切换。
技术规格上,模型支持最长 32k token 的输入上下文、30+ 种语言,提供 2B 和 8B 两种参数规模。在 BEIR、MIRACL 等文本检索基准以及 MMRet、DocRet 等多模态检索基准上,Qwen3-VL-Embedding 均处于开源前列,尤其在文档图像检索和视频帧检索这两个难度较高的场景上表现突出。
Qwen-Image-Layered:端到端图像分层生成,语义解耦的 RGBA 图层输出
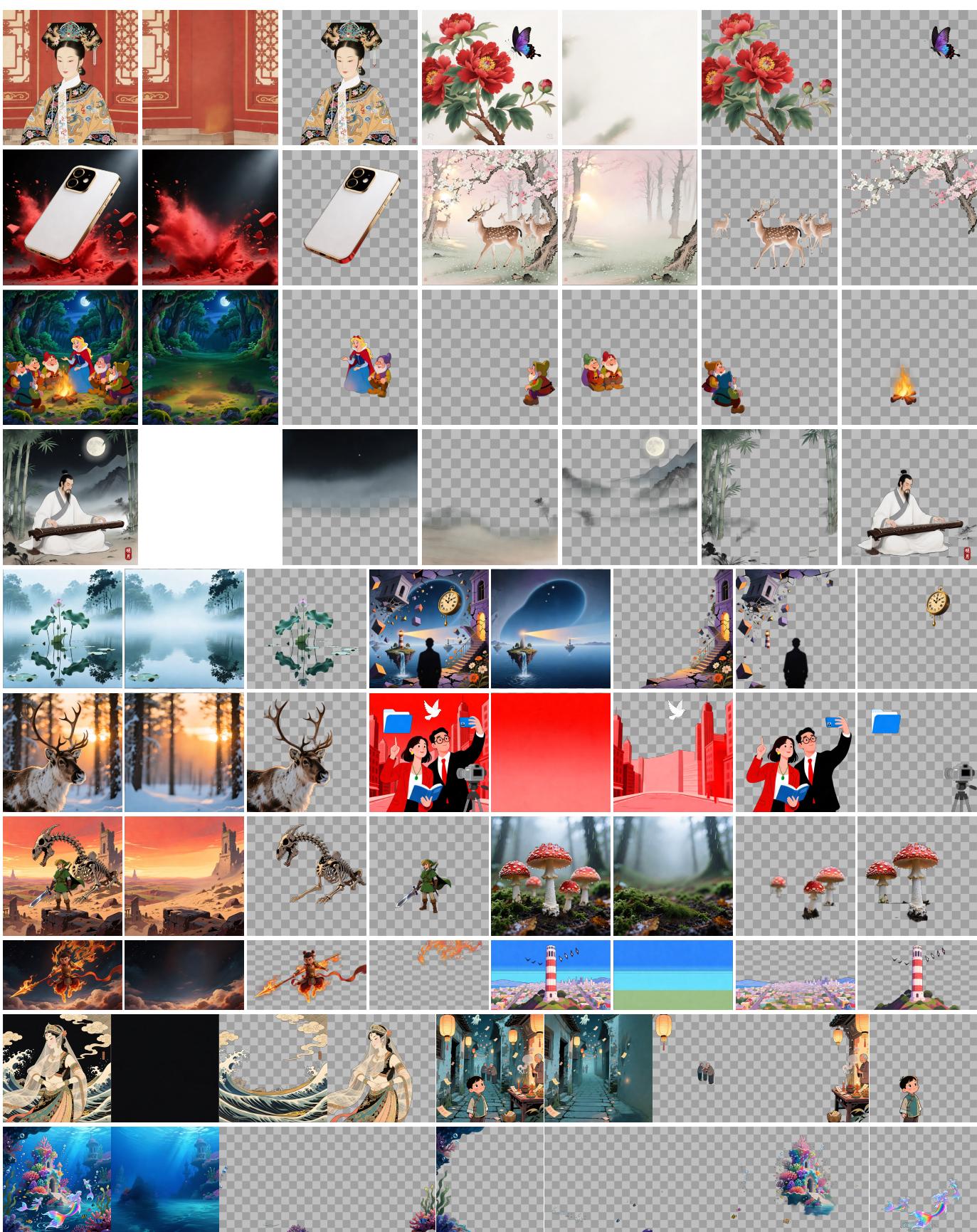
Qwen-Image-Layered 是通义实验室在图像生成领域的一次创新突破——它不再生成单张合并的 RGB 图,而是直接输出多个语义解耦的 RGBA 图层,每个图层对应图像中一个独立的语义对象,且自带透明通道(Alpha)。这一能力让 AI 图像生成首次具备接近专业设计软件的图层化表示,大幅降低后期编辑成本。
模型由三大组件构成:RGBA-VAE 负责将带透明通道的图层编码到潜在空间;VLD-MMDiT(可变长度分解 MMDiT)是核心扩散变换器,支持动态数量的图层并行生成;可变长度分解模块根据图像复杂度自适应决定分解为几个图层,而非固定数量。整体采用端到端训练,不依赖预训练的分割模型或后处理步骤。
从应用价值来看,Qwen-Image-Layered 生成的图层可直接导入 Photoshop、Figma 等设计工具,每个图层独立可编辑,修改某个对象不影响其他内容。这对平面设计、游戏资产制作、电商海报生成等场景具有直接商业价值,是将生成式 AI 真正融入专业设计工作流的重要一步。