速览 · Quick View
| # | 技术方向 | 论文数 | 代表作 | 关键指标 |
|---|---|---|---|---|
| 1 | 稀疏注意力 | 30+ | NSA (167↑), FASA (148↑) | 9x 前向加速 |
| 2 | KV Cache 优化 | 28+ | InfiniteHiP (149↑), HERMES | 3M tokens 单卡 |
| 3 | 投机解码 | 24+ | LayerSkip (80↑), Medusa (59↑) | 2-3x 推理加速 |
| 4 | 量化 | 23+ | QAT Scaling Law (76↑), BiLLM (50↑) | 1-bit 极限 |
| 5 | 高效架构 | 14+ | Mamba (150↑), Kimi Linear (125↑) | 线性复杂度 |
| 6 | 高效注意力内核 | 13+ | SageAttention 1/2/3, TransMLA (57↑) | FP4 推理 |
| 7 | 剪枝与压缩 | 11+ | Minitron (58↑), SEAP (66↑) | 40% 参数压缩 |
| 8 | 分布式训练 | 20+ | DeepSpeed-Chat, Ring Attention | 跨节点通信 |
| 9 | 蒸馏 | 5+ | Distillation Scaling Laws (47↑) | 小模型逼近大模型 |
| 10 | 服务系统 | 9+ | SGLang, Inferix (50↑) | 端到端 serving |
全景概述:AI 基础设施的三大核心矛盾
大语言模型的能力正在以前所未有的速度扩展,但算力基础设施的发展始终面临三组根本性的张力。理解这些矛盾,是理解过去三年 150+ 篇推理加速与训练优化论文的关键线索。
矛盾一:注意力 vs 效率。标准 Transformer 的自注意力机制是 O(n²) 复杂度,当序列长度从 4K 扩展到 128K 甚至 1M 时,计算与内存开销呈爆炸式增长。稀疏注意力(NSA[1]、FASA[2])、线性注意力(Kimi Linear[5])、状态空间模型(Mamba[4])从不同角度挑战这一瓶颈,但每种方案都在准确率与效率之间做出不同的取舍。NSA 证明了稀疏注意力可以在 64K 上下文上实现 9 倍前向加速的同时不牺牲甚至提升下游性能,打破了"稀疏 = 降质"的传统认知。
矛盾二:精度 vs 性能。量化技术从 FP16 一路推进到 INT4、INT2 乃至 1-bit(BiLLM[12]),每一步都在精度损失与推理加速之间寻找 Pareto 最优。QAT Scaling Law[11] 首次系统性地研究了量化与模型规模的交互关系,而 SageAttention3[15] 将 FP4 引入注意力计算内核,将硬件级优化推向极限。与此同时,"Give Me BF16"[24] 的反思性工作提醒社区:激进量化在某些场景下的代价可能被低估。
矛盾三:单卡 vs 分布式。大模型训练不可避免地走向多卡、多节点,但通信开销往往成为扩展的瓶颈。Ring Attention 通过环形通信实现了序列维度的并行,DeepSpeed-Chat[22] 将 RLHF 训练的工程复杂度降低了一个数量级,DisTrO 探索了完全去中心化的训练范式。在推理侧,KV Cache 管理(InfiniteHiP[3]、HERMES[16])使单卡处理百万级 token 成为可能,从另一个方向缓解了对分布式推理的依赖。
技术全景图:6 大方向 × 代表性工作
下图以功能维度梳理了 AI 推理加速与训练优化领域的技术全景。六大方向各有侧重,但彼此之间存在大量交叉 — 例如 NSA 同时涉及稀疏注意力和硬件对齐内核设计,MiniCPM4 则融合了稀疏注意力、量化和系统工程。
注意力优化
NSA (167↑), FASA (148↑), SpargeAttn (60↑), SageAttention 1/2/3, Sliding Tile Attention (51↑), Delta Attention (48↑)
内存管理
InfiniteHiP (149↑), HERMES (74↑), SnapKV, PyramidKV, CacheBlend, LongLoRA (88↑)
计算加速
LayerSkip (80↑), Medusa (59↑), Eagle, Sequoia, MiniCPM4 (83↑)
参数压缩
BiLLM (50↑), QAT Scaling Law (76↑), Minitron (58↑), SEAP (66↑), Pruning Gamble (67↑)
架构革新
Mamba (150↑), Kimi Linear (125↑), Jamba (112↑), Griffin (56↑), Falcon-H1 (70↑), TinyLlama (95↑)
系统工程
SGLang, Inferix (50↑), DeepSpeed-Chat (45↑), Ring Attention, DisTrO, SmallThinker (58↑)
稀疏注意力 — NSA & FASA 深度解析
NSA: Natively Sparse Attention for Long-Context Training
NSA 是稀疏注意力领域的里程碑 — 它是第一个可原生训练的稀疏注意力机制,打破了此前稀疏注意力仅能用于推理加速的限制。其核心设计是三路径并行注意力架构:
压缩 Token 路径 (Compressed Tokens):将连续的 KV 块通过可学习的线性投影压缩为少量代表性 token,捕捉全局粗粒度信息。选择 Token 路径 (Selected Tokens):基于压缩 token 的注意力分数,选择 top-k 个最相关的原始 token 块,捕捉局部细粒度信息。滑动窗口路径 (Sliding Window):保留最近的局部上下文,确保近距离依赖的完整性。三条路径的输出通过可学习的门控机制融合。
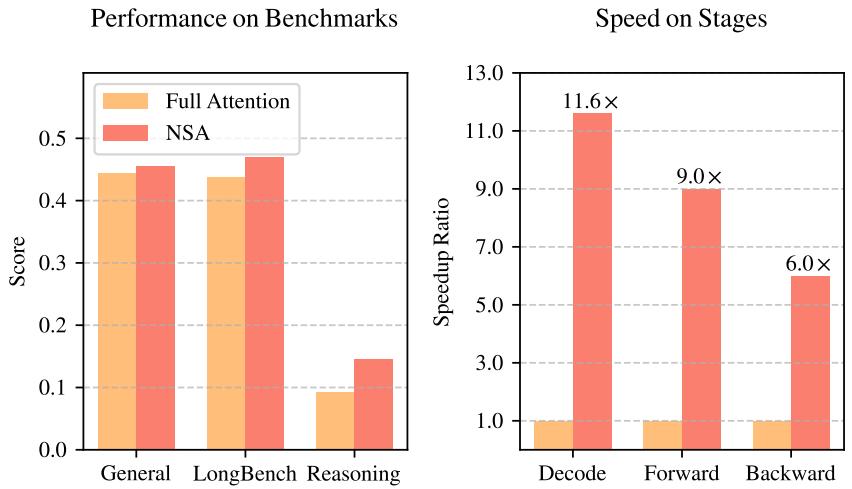
关键的工程创新在于硬件对齐的 Triton 内核设计:所有操作都以与 GPU SRAM 块大小对齐的粒度执行,最大化内存带宽利用率。性能数据极为突出:在 64K 上下文长度下,前向传播加速 9.0x,反向传播加速 6.0x,解码加速 11.6x。更重要的是,在 LongBench 基准上平均得分 0.469,超越全注意力 (Full Attention) 的 0.437,证明了稀疏注意力不仅不损失质量,甚至可以通过减少噪声注意力来提升性能。
FASA: Frequency-Aware Sparse Attention
FASA 从一个独特的视角切入稀疏注意力:RoPE 旋转位置编码在频率域上的特性。论文发现,RoPE 的不同频率分量对注意力分数的贡献差异巨大 — 低频分量编码全局位置关系,高频分量编码局部 token 级关系。基于此,FASA 在频率-块(frequency-chunk)级别进行稀疏化:对低频分量使用全量 KV Cache,对高频分量仅保留少量代表性 token。
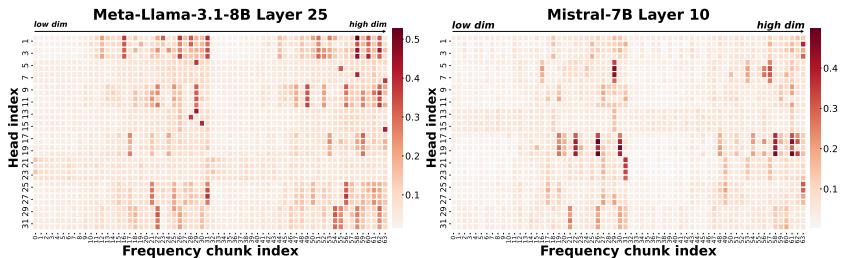
实验结果显示,FASA 在仅使用 18.9% 的 KV Cache 的情况下,在多数长上下文基准上达到了接近 100% 全 KV Cache 性能。在 AIME24 数学推理基准上,FASA 实现了 2.56x 加速,同时保持了与全注意力几乎一致的准确率。这意味着约 80% 的 KV Cache 是"注意力噪声",对最终结果贡献微乎其微。
KV Cache 优化 — InfiniteHiP 深度解析
InfiniteHiP: Extending Language Model Context Up to 3 Million Tokens
InfiniteHiP 解决了一个极端实际的问题:如何在单张 48GB GPU 上处理 300 万 token 的超长上下文。其核心技术路线是"层级化 token 剪枝 + RoPE 调整 + KV Cache 卸载"的模块化组合,且完全不需要额外训练。
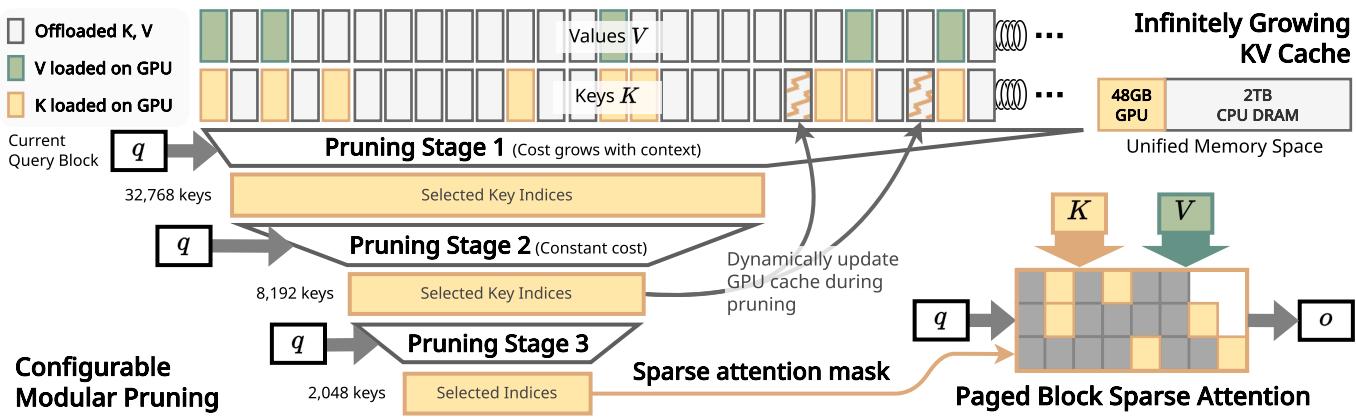
层级化 Token 剪枝 (Hierarchical Token Pruning):将 token 序列按层级组织,在注意力计算前逐层筛选,仅保留与当前 query 最相关的 token 子集。每一层剪枝比例可独立配置,浅层保留更多 token(捕捉局部模式),深层更激进剪枝(聚焦全局语义)。
RoPE 偏移调整 (RoPE Adjustment):剪枝后 token 的位置编码不连续,直接使用原始 RoPE 会引入位置信息错误。InfiniteHiP 通过动态重映射剪枝后 token 的位置索引,确保 RoPE 编码的连续性。
KV Cache 卸载 (Offloading):将不在当前活跃窗口内的 KV Cache 卸载到 CPU 内存或磁盘,按需加载回 GPU。结合异步预取策略,将卸载延迟隐藏在计算时间内。
在 DeepSeek R1 上的验证尤为关键:将原生 128K 上下文模型扩展到 1M token,在 Needle-in-a-Haystack 测试中无性能退化。这证明了 InfiniteHiP 不仅是理论可行的,而且可以直接应用于最新的生产级模型。
相关重要工作
HERMES (74↑)
arXiv: 2601.14724。基于分层 KV Cache 驱逐策略的长上下文推理优化方案,通过选择性保留高重要性 token 的 KV 对来降低内存占用,兼顾推理质量与效率。
SnapKV & PyramidKV
SnapKV 通过观察注意力分数的"快照"模式来选择性压缩 KV Cache;PyramidKV 则以金字塔结构在不同层使用不同大小的 Cache,浅层保留完整信息,深层激进压缩。
CacheBlend
针对 prefix caching 场景,CacheBlend 通过混合重新计算与缓存复用策略,在共享前缀的多请求服务中实现了显著的内存节省,同时保持输出质量。
高效架构 — Mamba & Kimi Linear 深度解析
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Mamba 是状态空间模型(SSM)在语言建模领域的突破性工作。传统 SSM(如 S4)使用固定的状态转移参数,无法根据输入内容进行选择性信息传递。Mamba 的核心创新是选择性 SSM (Selective SSM):将状态转移矩阵的参数(Δ, B, C)变为输入相关的(input-dependent),使模型能够根据当前 token 的内容决定保留或遗忘哪些信息。
这一看似简单的修改带来了双重优势:O(n) 线性时间复杂度(相比 Transformer 的 O(n²)),以及与 Transformer 可比的建模能力。在推理阶段,Mamba 的状态大小固定,不需要随序列长度线性增长的 KV Cache,使其在极长序列推理上具有天然优势。Mamba 在多项语言建模基准上达到了与同等规模 Transformer 相当或更优的性能,同时推理吞吐量提升 5 倍以上。
Kimi-K2: From Linear Attention to Foundation Model
如果说 Mamba 证明了线性注意力的可行性,Kimi Linear 则证明了线性注意力可以在实际产品级模型中替代标准注意力。Moonshot AI 的核心技术方案是 KDA (Key-aware Delta rule Attention) — 一种基于通道级门控 delta 规则的线性注意力变体,配合 NoPE MLA 混合架构:每 4 层中有 3 层使用 KDA 线性注意力,1 层使用标准 MLA(Multi-head Latent Attention)。
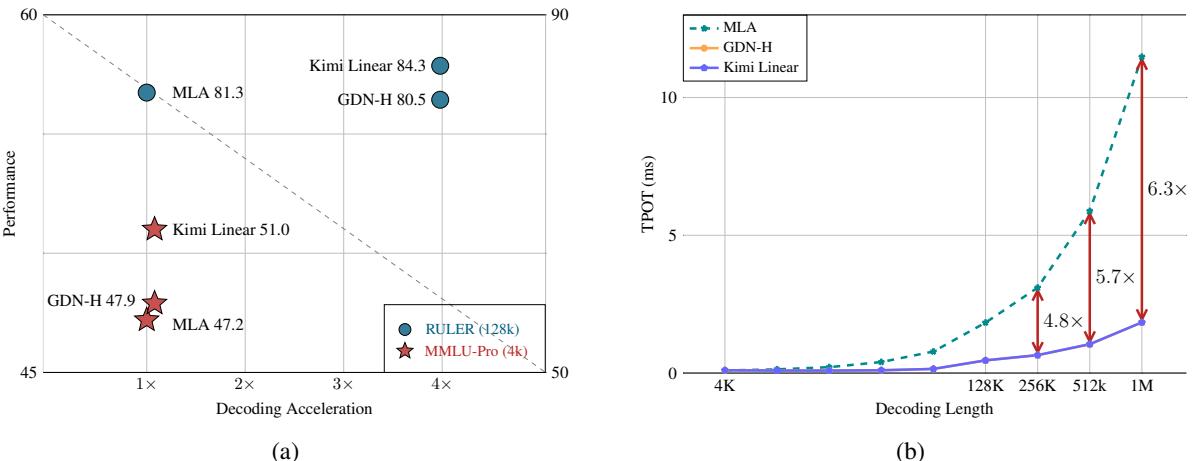
这种 3:1 混合策略的性能令人瞩目:
| 指标 | Kimi Linear (KDA+MLA) | 纯 MLA | 提升 |
|---|---|---|---|
| MMLU-Pro | 51.0 | 47.2 | +3.8 |
| RULER 128K | 84.3 | 81.3 | +3.0 |
| KV Cache 用量 | -75% | 基线 | 4x 减少 |
| 解码吞吐量 @1M | 6.3x | 基线 | — |
75% 的 KV Cache 减少意味着在等量 GPU 内存下可以服务 4 倍更多的并发请求。6.3 倍的解码吞吐量提升使百万级 token 上下文的实时推理成为可能。Kimi Linear 证明了线性注意力不是"退而求其次"的选择,而是可以在质量和效率上同时优于标准注意力。
更多高效架构
Jamba (112↑)
arXiv: 2403.19887。AI21 Labs 提出的 Transformer-Mamba 混合架构,将 SSM 层与 Transformer 层交错排列,并引入 MoE(混合专家)机制,在保持 Transformer 推理质量的同时大幅降低长序列的内存和计算开销。
TinyLlama (95↑)
arXiv: 2401.02385。1.1B 参数模型在 3T token 上预训练,证明了小模型通过充分训练可以达到远超预期的性能。开源社区贡献的训练工程最佳实践。
Griffin (56↑) & Falcon-H1 (70↑)
Griffin (arXiv: 2402.19427) 由 Google DeepMind 提出,将门控线性循环层与局部注意力混合。Falcon-H1 (arXiv: 2507.22448) 则是 Mamba-2 架构的大规模验证,在多项基准上与同等规模 Transformer 模型持平。