📋 速览目录
- 01Less is Enough — 2000 条数据媲美 30 万条
- 02GLM-5 — 首破 AI Index 50 分的开放权重模型
- 03SkillsBench — Agent 技能包真的有用吗
- 04ERL — 让 AI 学会分析错题本
- 05SAE Sanity Check — 可解释性工具不可信
- 06SQuTR — 语音助手噪声抗性基准
- 07BitDance — 二进制 token 图像生成
- 08AutoWebWorld — 给网页 Agent 建虚拟驾校
- 09SLA2 — 视频 AI 提速 18 倍
- 10RynnBrain — 阿里达摩院具身基础模型
这一周的 AI 论文圈, 可以用一个词概括: 「进化」。
模型不再只是被动地吞噬数据——它们开始像人类一样反思失败 (ERL), 学会用更少的数据做更多的事 (Less is Enough), 甚至开始质疑自己的「记忆」到底有没有意义 (SAE Sanity Check)。
与此同时, 图像生成领域迎来了一次「二进制新范式」——BitDance 用 0 和 1 的组合就能画出惊艳的图片; 而具身智能领域, RynnBrain 试图给机器人装上一颗真正理解物理世界的「大脑」。泡一杯咖啡, 我们开始。
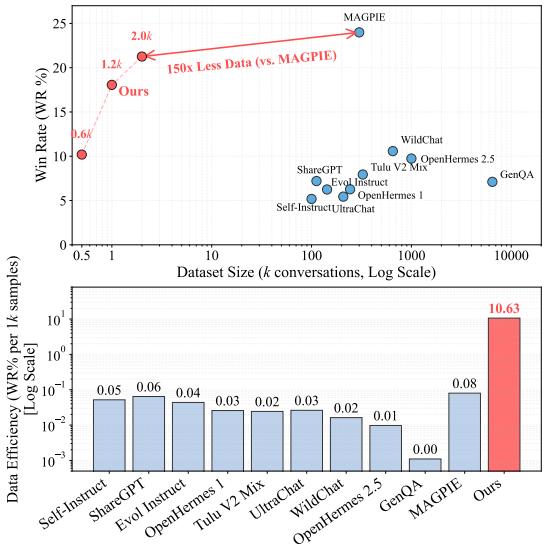
Less is Enough: 2000 条数据就能媲美 30 万条的秘密
这篇论文 219 upvotes 高居热榜第一, 说明 AI 社区对一个问题的焦虑达到了顶点: 训练数据到底还要堆多少?
答案可能让你意外: 不用堆了, 2000 条就够了——但前提是你得选「对」的 2000 条。
传统做法就像在图书馆随机借 30 万本书来学习, 看似覆盖面广, 实际上大量重复。这篇论文提出了 FAC (Feature Activation Coverage) 指标——你可以把它理解为「模型的知识地图完整度评分」: 100% 意味着所有知识区域都被覆盖, 低于 100% 说明有盲区。核心思想是: 不要在文本表面衡量数据多样性, 而是深入模型内部, 看看哪些「知识区域」是空白的, 然后精准补齐。
具体怎么做? 用一种叫 SAE (稀疏自编码器) 的工具给模型做「CT 扫描」, 找出哪些任务相关的特征在现有数据中没有被覆盖, 然后用 LLM 合成专门激活这些「缺失特征」的新数据。
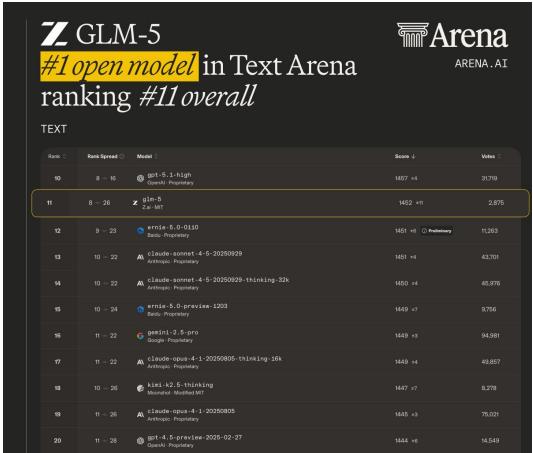
GLM-5: 从「写代码」到「独立经营一家公司」的 AI 进化
如果说去年的大模型竞赛还停留在「谁更会聊天」的阶段, 那 GLM-5 的出现, 标志着战场已经转移到了一个全新的维度: 谁能独立完成复杂的现实世界任务。
智谱联合清华发布的 GLM-5, 是一个拥有 744B 总参数 (40B 活跃参数) 的 MoE 架构开放权重 (open weights) 模型, 总训练量达到 28.5 万亿 token。但参数量和数据量只是冰山一角, 真正让人眼前一亮的是两项技术和一个关键工程突破:
采用 DeepSeek 提出的 DSA (DeepSeek Sparse Attention) 技术: 传统注意力机制在处理长上下文时, 计算量随序列长度平方增长。DSA 通过动态识别「哪些 token 重要」, 将注意力计算量降低约 1.5-2 倍, 同时不损失长上下文理解能力。就像一个侦探审讯, 不是把所有证人都叫来, 而是直接锁定关键证人深度盘问。
异步强化学习基础设施 + Agent RL 算法: 传统 RL 训练中, GPU 在等待 Agent 与环境交互时大量闲置。GLM-5 将推理和训练完全解耦, 让 GPU 始终保持忙碌, 大幅提升了后训练效率。更重要的是, 异步 Agent RL 算法让模型能从长期复杂的交互中持续学习, 而不仅仅是短期问答。