速览目录 · 全部 43 篇
| # | 论文 | 领域 | Votes | 一句话 |
|---|---|---|---|---|
| 1 | Utonia | 3D/点云 | 126 | 一个编码器统一五大点云域,跨域涌现提升机器人操作 |
| 2 | UniG2U-Bench | 多模态评测 | 77 | 30+模型评测发现统一模型普遍弱于基础VLM |
| 3 | Meta FAIR 多模态 | 多模态预训练 | 61 | 从头预训练揭示 RAE/数据协同/MoE 四大设计准则 |
| 4 | BeyondSWE | Coding Agent | 49 | 500个跨仓库任务暴露代码Agent能力缺口 |
| 5 | Mix-GRM | RL/奖励模型 | 30 | 广度+深度双CoT让奖励模型提升8.2% |
| 6 | Qwen3-Coder-Next | 代码模型 | 28 | 80B/3B MoE代码Agent逼近十倍体量模型 |
| 7 | Kling-MotionControl | 视频生成 | 24 | 分治策略实现身体/面部/手部精细角色动画 |
| 8 | SteerEval | LLM 评测 | 21 | 三层级行为控制评测揭示细粒度可控性鸿沟 |
| 9 | PRISM | 推理/PRM | 18 | PRM引导推理让20B模型追平120B |
| 10 | NE-Dreamer | 世界模型 | 15 | 下一嵌入预测替代像素重建增强记忆任务 |
| 11 | Kiwi-Edit | 视频编辑 | 14 | 指令+参考图双引导的通用视频编辑方法 |
| 12 | Code2Math | 数学推理 | 13 | 让代码Agent通过探索自动进化数学问题 |
| 13 | 人类 vs LLM | 认知科学 | 10 | 人类和LLM在概率推断上的系统性分歧 |
| 14 | Surgical Post-Training | 后训练 | 9 | 精准后训练:修正错误同时保留知识 |
| 15 | InfoPO | Agent | 9 | 信息驱动策略优化让Agent主动澄清模糊需求 |
| 16 | BBQ-to-Image | 文生图 | 8 | 数值化边界框+颜色控制的精确文生图 |
| 17 | LLM 溢出能量 | 理论 | 8 | 把LLM softmax分类器重新解读为能量模型 |
| 18 | NOVA | 视频编辑 | 7 | 稀疏控制+密集合成的无配对视频编辑 |
| 19 | Track4World | 3D追踪 | 7 | 前馈式世界坐标系稠密3D像素追踪 |
| 20 | AgentGuard | Agent安全 | 7 | 教Agent在多步工具调用中学会拒绝 |
| 21 | CFG-Ctrl | 扩散模型 | 6 | 控制论视角的无分类器扩散引导 |
| 22 | Chain of World | 具身智能 | 6 | 潜在运动空间中做世界模型推理的VLA |
| 23 | SciDER | 科研Agent | 4 | 以数据为中心的端到端科研自动化Agent |
| 24 | DREAM | 多模态 | 3 | 统一视觉理解与文生图的双向模型 |
| 25 | ParEVO | HPC | 3 | Agentic进化合成不规则数据的并行代码 |
| 26 | 算法核收敛 | 理论 | 3 | Transformer收敛到不变的算法核心 |
| 27 | QEDBENCH | 数学评测 | 3 | 量化大学级数学证明自动评测的对齐差距 |
| 28 | APRES | 学术Agent | 2 | 论文修订与评估的自动化Agent系统 |
| 29 | AgentConductor | 多Agent | 2 | 多Agent拓扑进化的竞赛级代码生成 |
| 30 | HateMirage | 安全 | 1 | 解码伪仇恨和隐性网络暴力的多维数据集 |
| 31 | DynaMoE | MoE | 1 | 动态Token级专家激活+层自适应容量 |
| 32 | 视频Token缩减 | 效率 | 1 | 局部+全局上下文优化的高效视频LLM |
| 33 | GroupGPT | Agent | 1 | Token高效且隐私保护的多用户聊天Agent |
| 34 | Whisper-RIR-Mega | 语音 | 1 | 配对干净/混响语音的ASR鲁棒性基准 |
| 35 | SGDC | 医学影像 | 1 | 结构引导动态卷积的医学图像分割 |
| 36 | LLM社媒模拟 | 社会计算 | 1 | 评测LLM模拟社交媒体用户评论的有效性 |
| 37 | 安全扩散引导 | 安全 | 1 | 条件激活传输的文生图安全引导 |
| 38 | 鲁棒遗忘 | 隐私 | 1 | 偏差下的鲁棒机器遗忘 |
| 39 | LFPO | 扩散模型 | 1 | Masked扩散模型的无似然策略优化 |
| 40 | Words & Weights | 多轮交互 | 1 | 多轮交互中词语与权重的协同适应 |
| 41 | 快速矩阵乘法 | 算法 | 0 | 用翻转图框架发现小格式快速矩阵乘法 |
| 42 | 射线路径采样 | 通信 | 0 | 变换不变的生成式射线路径采样 |
| 43 | 图黎曼粘合 | 图学习 | 0 | 多域黎曼图粘合构建图基础模型 |
今天 43 篇论文,两条主线清晰:统一化与通用化——Utonia 用一个编码器覆盖遥感/LiDAR/室内/物体/视频五大点云域,126 票领跑;UniG2U-Bench 系统评测统一多模态模型的生成-理解耦合效果;Meta FAIR 从头预训练揭示多模态 MoE 的四大设计准则。代码 Agent 走出舒适区——BeyondSWE 把评测从单仓库修 Bug 扩展到跨仓库推理、依赖迁移和整库生成,最强模型成功率不到 45%;Qwen3-Coder-Next 用 80B 总参/3B 激活的 MoE 架构在 SWE-Bench 上逼近体量大一个数量级的模型。
Insight:当研究者同时追求「一个模型解决所有任务」和「一个 Agent 应对所有工程场景」,AI 的两个前沿——表征统一化和Agent 通用化——正在从不同方向逼近同一个目标:通用人工智能的基础能力底座。
Utonia: 一个编码器统一所有点云域——从遥感到自动驾驶到机器人

点云数据来自遥感、自动驾驶 LiDAR、室内 RGB-D、CAD 模型等截然不同的传感器,尺度、密度、采样模式差异巨大,此前的自监督点云模型只能在单一域内训练。Utonia 迈出关键一步:用一个 Point Transformer 编码器,在五个域(遥感、室外LiDAR、室内 RGB-D、物体CAD、视频点云)上联合自监督预训练。
核心技术挑战在于域间极端的分布差异。Utonia 采用自适应颜色/法向量输入机制(adaptive C/N),当某些域缺少颜色或法向量信息时自动降级,避免模型被域特异性的捷径特征主导。预训练使用 masked autoencoding 范式,将离散 token 的前向过程建模为逐步 mask,逆过程预测被 mask 的 token。
实验显示,联合训练不仅不降低各域性能,反而带来跨域涌现行为:在 ScanNet 语义分割上超越单域预训练 2.1 mIoU,在 nuScenes 检测上提升 1.8 NDS。更值得关注的是 Utonia 在下游的泛化能力——将 Utonia 特征接入视觉语言动作策略(VLA),机器人操作成功率提升 8.3%;接入视觉语言模型用于空间推理也有增益。
UniG2U-Bench: 统一多模态模型的生成能力真的能提升理解吗?
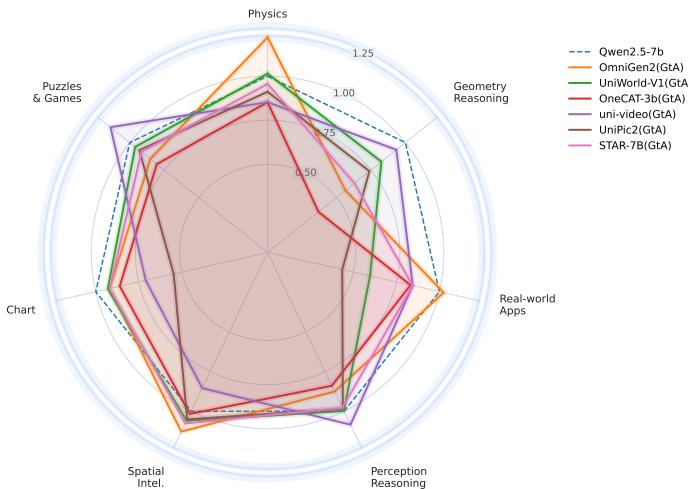
统一多模态模型(如 Janus、Show-o、BAGEL)宣称「理解+生成一体化」带来互利,但生成能力是否真的提升了理解这一核心问题一直缺乏系统验证。UniG2U-Bench(Generation-to-Understanding)是目前最全面的统一模型理解评测基准,覆盖 7 大评测维度、30 个子任务,涉及空间推理、视觉错觉、多轮推理等需要不同程度视觉变换的场景。
研究团队对 30+ 模型进行了大规模评测,严格配对统一模型与其基础 VLM,在匹配推理协议下隔离「生成-to-理解」(G2U)效果。三个核心发现:(1) 统一模型普遍不如其基础 VLM;(2) 只在空间智能、视觉错觉和多轮推理子任务上有提升;(3) 具有相似推理结构的任务和共享架构的模型表现出相关的行为模式。
这项工作为「统一 vs 分离」的架构辩论提供了迄今最系统的实证证据。结论并非全盘否定统一模型,而是指出当前的统一训练策略需要更多样的数据和新范式才能真正释放生成对理解的辅助潜力。
Meta FAIR: 从头预训练揭示多模态基础模型的四大设计准则
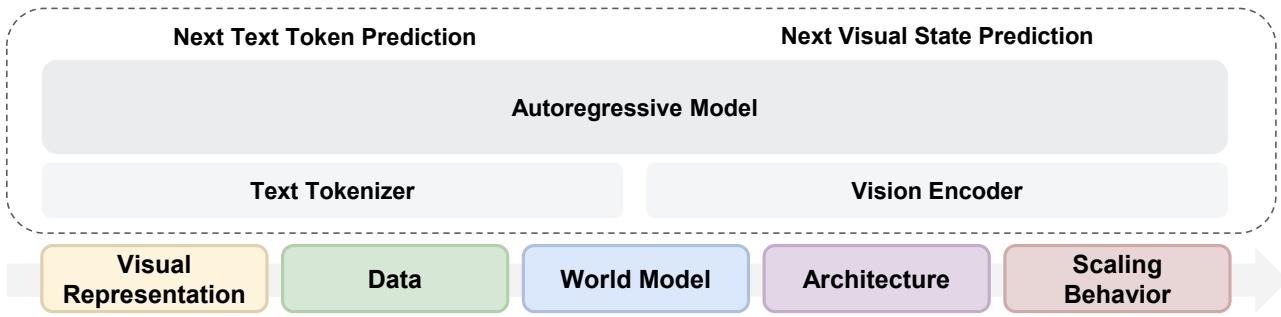
视觉世界是推动基础模型超越语言的关键维度,但原生多模态模型的设计空间仍然不透明。来自 Meta FAIR + NYU(Yann LeCun 等参与指导)的团队通过严格控制变量的从头预训练实验,在不依赖语言预训练的前提下,系统性地隔离多模态预训练的核心因素。
研究采用 Transfusion 框架——语言用 next-token prediction,视觉用 diffusion。四个关键发现:(1) RAE 是最优统一视觉表征,同时擅长理解和生成;(2) 视觉和语言数据互补,联合训练产生跨模态协同;(3) 世界建模能力从通用训练中自然涌现;(4) MoE 架构高效且自然诱导模态专业化。
通过 IsoFLOP 分析,团队揭示了关键的缩放不对称性:视觉比语言需要更多数据。MoE 恰好能调和这种不对称——为语言提供高模型容量,同时适应视觉的数据密集特性。这篇论文为多模态基础模型的设计提供了迄今最系统的实验指导。
BeyondSWE: 代码Agent能否超越单仓库修Bug?500个真实跨域任务给出答案
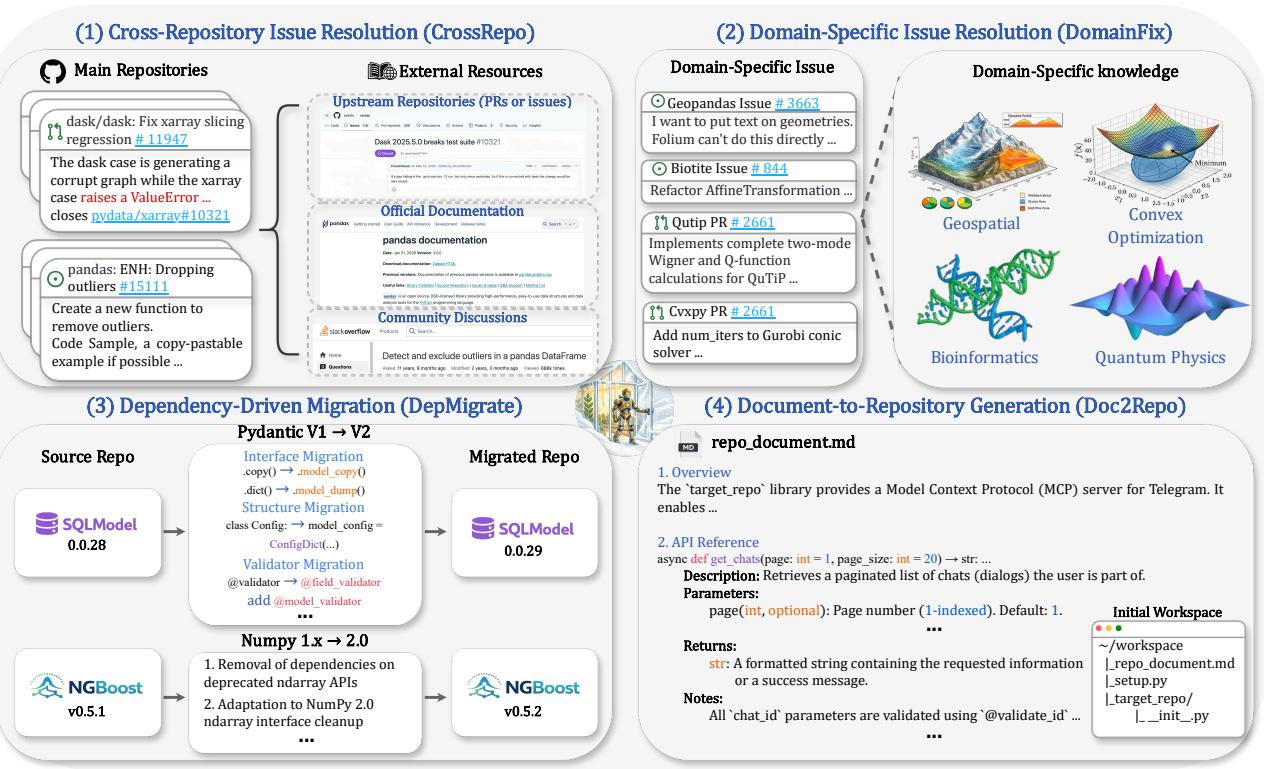
SWE-bench 已成为代码 Agent 的标准评测,但其任务本质上仍局限于单仓库内的函数级 Bug 修复。BeyondSWE 沿解决范围和知识范围两个轴扩展评测,包含 500 个真实实例,覆盖四个全新设置:CrossRepo(跨仓库推理)、DomainFix(领域专用修复)、DepMigrate(依赖迁移)、Doc2Repo(整库生成)。
实验结果暴露了当前代码 Agent 的严重能力缺口:即使是前沿模型,成功率也低于 45%,且没有任何模型在所有任务类型上一致表现良好。团队还开发了 SearchSWE 框架集成深度搜索,但搜索增强效果并不一致,有时甚至降低性能。
Mix-GRM: 广度+深度双通道思考链让生成式奖励模型提升 8.2%
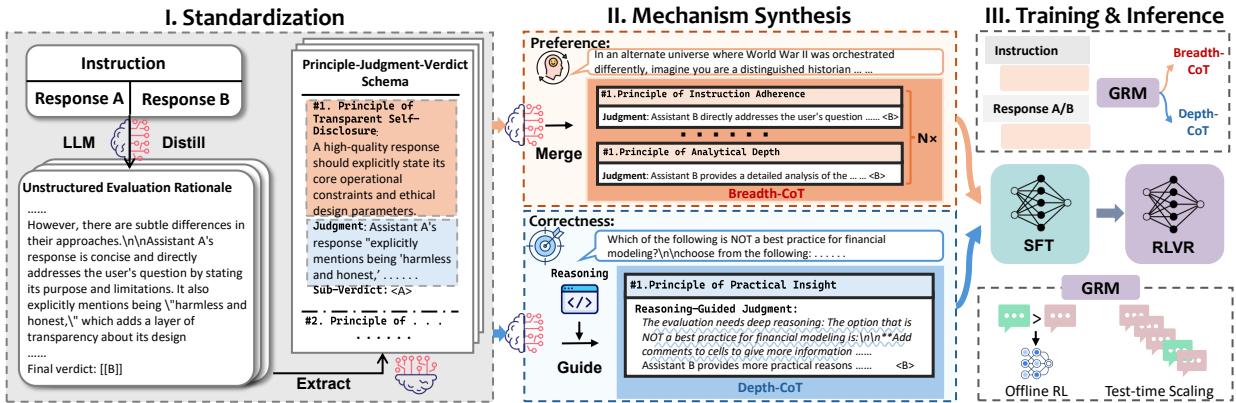
生成式奖励模型(GRM)通过输出推理过程再给出评分,已被证明比直接打分更可靠。但现有方法盲目加长 CoT,忽略了不同推理机制的效果差异。Mix-GRM 将推理拆分为两种结构化通道:Breadth-CoT(广度思考,多维度原则覆盖,适合主观偏好类任务)和 Depth-CoT(深度思考,逐步逻辑验证,适合客观正确性任务)。
训练采用 SFT + RLVR 两阶段。特别值得注意的是 RLVR 阶段出现的涌现极化现象:模型自发地将推理风格与任务需求匹配——面对主观任务自动切换到 B-CoT,面对客观任务自动切换到 D-CoT。在 5 个基准上平均超出领先开源奖励模型 8.2%。