📋 速览目录 · 全部 28 篇
| # | 论文 | 领域 | Votes | 一句话 |
|---|---|---|---|---|
| 1 | Trinity of Consistency | 世界模型 | 178 | 提出通用世界模型的「一致性三位一体」理论框架 + CoW-Bench |
| 2 | DPE | 多模态训练 | 142 | 诊断驱动迭代训练,工具增强数据进化修补 LMM 盲区 |
| 3 | MobilityBench | Agent 基准 | 90 | 高德真实查询构建路线规划 Agent 基准,偏好约束仍是难题 |
| 4 | OmniGAIA | 全模态 Agent | 46 | 360 任务全模态 Agent 基准 + OmniAtlas 工具推理 Agent |
| 5 | CapImagine | 视觉推理 | 33 | 因果分析揭示潜空间推理两大断裂,文本想象反超 |
| 6 | EMPO² | Agent RL | 26 | 记忆增强探索 + 混合 on/off-policy,ScienceWorld +128.6% |
| 7 | AgentDropoutV2 | 多 Agent 系统 | 23 | 测试时纠错-或-剪枝,多 Agent 系统平均 +6.3% |
| 8 | SMTL | 深度搜索 | 15 | 并行搜索替代串行推理,BrowseComp 48.6% SOTA |
| 9 | MediX-R1 | 医学 AI | 13 | 开放式医学 RL,8B 超 MedGemma 27B |
| 10 | Hybridiff | 扩散加速 | 11 | 条件引导调度混合并行,SDXL 2.31x 加速无伪影 |
| 11 | VGG-T³ | 3D 重建 | 11 | 离线前馈大规模 3D 重建 |
| 12 | EmbodMocap | 具身 AI | 9 | 野外 4D 人体-场景重建服务具身 Agent |
| 13 | AI Gamestore | 评估 | 8 | 开放式可扩展通用智能评估 |
| 14 | Causal Motion Diffusion | 运动生成 | 5 | 因果运动扩散实现自回归动作生成 |
| 15 | GeoWorld | 世界模型 | 4 | 几何世界模型 |
| 16 | Retrieve and Segment | 分割 | 4 | 少样本检索弥合分割监督差距 |
| 17 | veScale-FSDP | 分布式训练 | 3 | 灵活高性能 FSDP 大规模训练 |
| 18 | General Agent Evaluation | 评估 | 3 | 通用 Agent 评估框架 |
| 19 | Risk-Aware World Model | 自动驾驶 | 2 | 风险感知世界模型预测控制 |
| 20 | QueryBandits | 幻觉缓解 | 2 | Bandit 方法缓解 LLM 幻觉 |
| 21 | Confusing Queries | 信息检索 | 2 | 人类困惑查询特征对检索的影响 |
| 22 | DLT-Corpus | NLP 语料 | 2 | 分布式账本技术大规模文本集 |
| 23 | MedCLIPSeg | 医学 AI | 2 | 概率视觉语言适配的高效医学分割 |
| 24 | Asymmetric Penalties | 模型训练 | 2 | 过度自信错误的非对称置信惩罚 |
| 25 | DyaDiT | 手势生成 | 1 | 多模态扩散双人交互手势 |
| 26 | MEG Transfer | 脑信号 | 1 | MEG 脑信号迁移学习与语音检测 |
| 27 | Thalamic Routing | 持续学习 | 0 | 丘脑路由皮层模块高效持续学习 |
| 28 | Echoes Over Time | 音频生成 | 0 | 视频到音频生成的长度泛化 |
今天的主线极其清晰:Agent 系统的全面进化。从理论层(Trinity of Consistency 提出世界模型的三维一致性公理),到训练层(DPE 诊断式迭代自进化、EMPO² 记忆增强 RL),到评估层(MobilityBench 真实路线规划、OmniGAIA 全模态 Agent),再到工程层(AgentDropoutV2 测试时纠错、SMTL 并行搜索),整条 Agent 研发链路上每个环节都有突破性工作出现。另一条暗线是「挑战直觉」:CapImagine 用因果分析证明潜空间推理根本没在推理,文本想象反而更强;Hybridiff 发现条件/非条件去噪路径可以作为并行维度,打破了扩散加速的传统思路。
Insight:当 Top 10 中 6 篇直接与 Agent 相关时,信号已经非常明确——2026 年的 Agent 研究正在从「能不能做」转向「做得稳不稳、评得准不准」。训练稳定性、评估可复现性、测试时自纠错,这些工程化难题正在成为新的论文主战场。
Trinity of Consistency: 提出通用世界模型的「一致性三位一体」理论框架
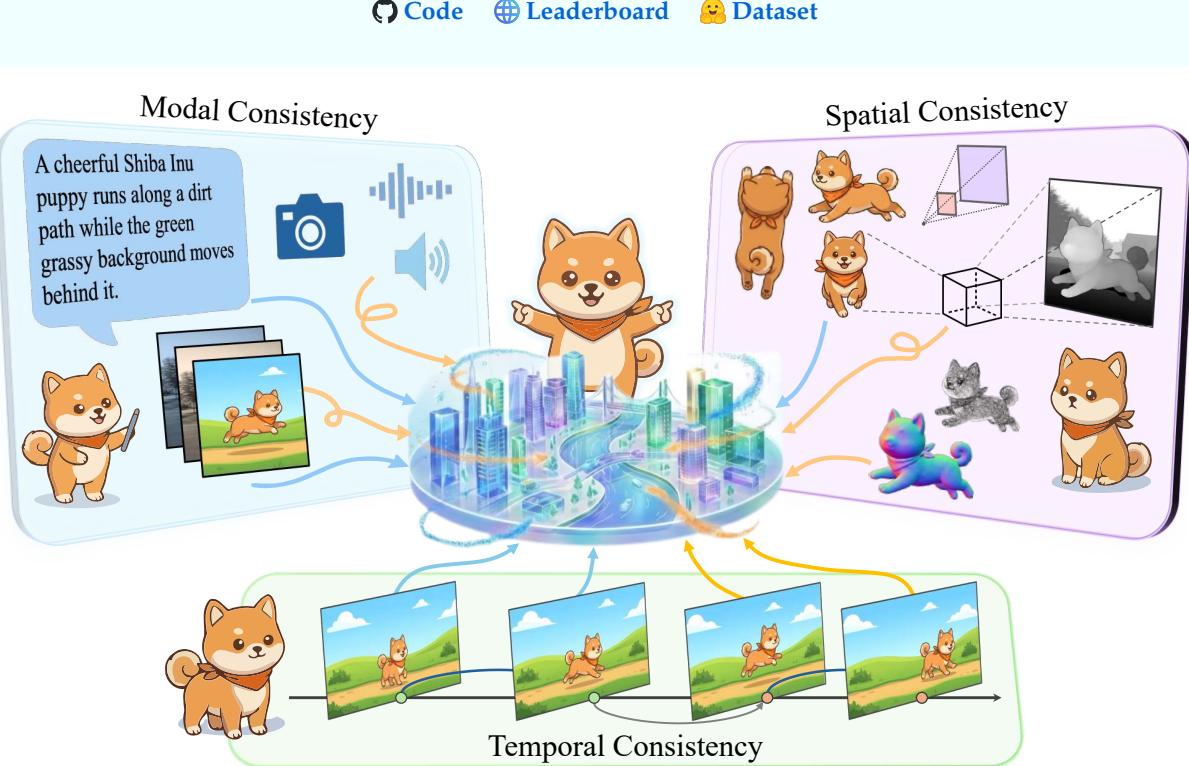
从 Sora 到各类视频生成模型,数据驱动的缩放定律已经证明可以近似物理动力学——但什么样的模型才能算「通用世界模型」?领域内缺少一个有原则的理论框架来定义世界模型必须满足的基本属性。这篇 178 票的综述正是要填补这个空白。
论文提出「一致性三位一体」作为通用世界模型的定义性原则:模态一致性(Modal Consistency)作为跨模态的语义接口,覆盖离散序列与连续流形的架构演进、意图对齐和认知循环;空间一致性(Spatial Consistency)作为几何基础,从 2D 代理流形到 NeRF 隐式场再到 3DGS 显式基元;时间一致性(Temporal Consistency)作为因果引擎,从频率稳定到物理合规到因果推理。三个维度相互正交又相互耦合,共同构成世界模型的完整性约束。
论文系统梳理了从松散耦合专用模块到统一架构的演进路径,并提出了 CoW-Bench(Consistency of World Benchmark),一个以多帧推理和生成为核心的基准,同时评估视频生成模型和统一多模态模型。超过 80 页的篇幅覆盖了世界模型研究的全景。
DPE: 诊断驱动迭代训练,让多模态大模型自己找到盲区并修补
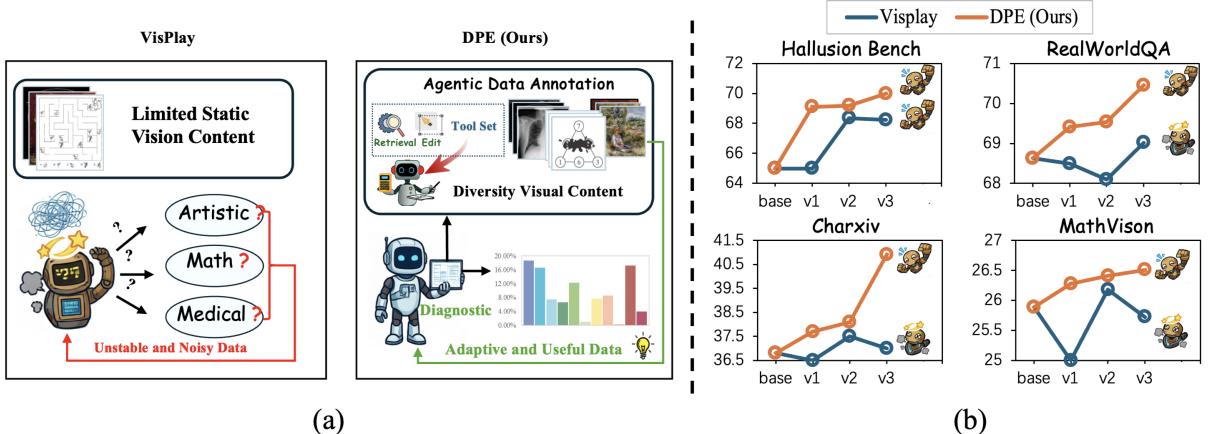
大型多模态模型(LMM)的训练仍然依赖静态数据和固定配方,难以诊断能力盲区或提供动态针对性强化。现有自进化框架有两个关键局限:(1)缺乏可解释的诊断——依赖困惑度等启发式信号而非显式失败归因;(2)视觉多样性匮乏——静态图像集限制了语义覆盖范围。
DPE(Diagnostic-driven Progressive Evolution)借鉴教育心理学中「诊断与定向纠正是学习效率的关键决定因素」的思想,构建了一个螺旋式进化循环:先由诊断 Agent 分析模型的失败模式,定位具体的能力弱点;然后动态优化训练数据混合比例;再由配备了图像搜索和编辑工具的多 Agent 系统生成针对弱点的多样化、逼真的多模态样本(不再局限于静态数据集或模板文本改写);最后进行定向强化学习——循环往复。
在 Qwen3-VL-8B 和 Qwen2.5-VL-7B 上的实验表明,DPE 在 11 个基准上取得持续稳定的提升。相比之下,先前的自进化框架虽能缓解幻觉但在数学、OCR 等长尾任务上无效——DPE 通过精准诊断+定向数据生成有效攻克了这些盲区。代码、模型和数据已开源。
MobilityBench: 高德真实查询构建路线规划 Agent 基准,偏好约束仍是 LLM 难题
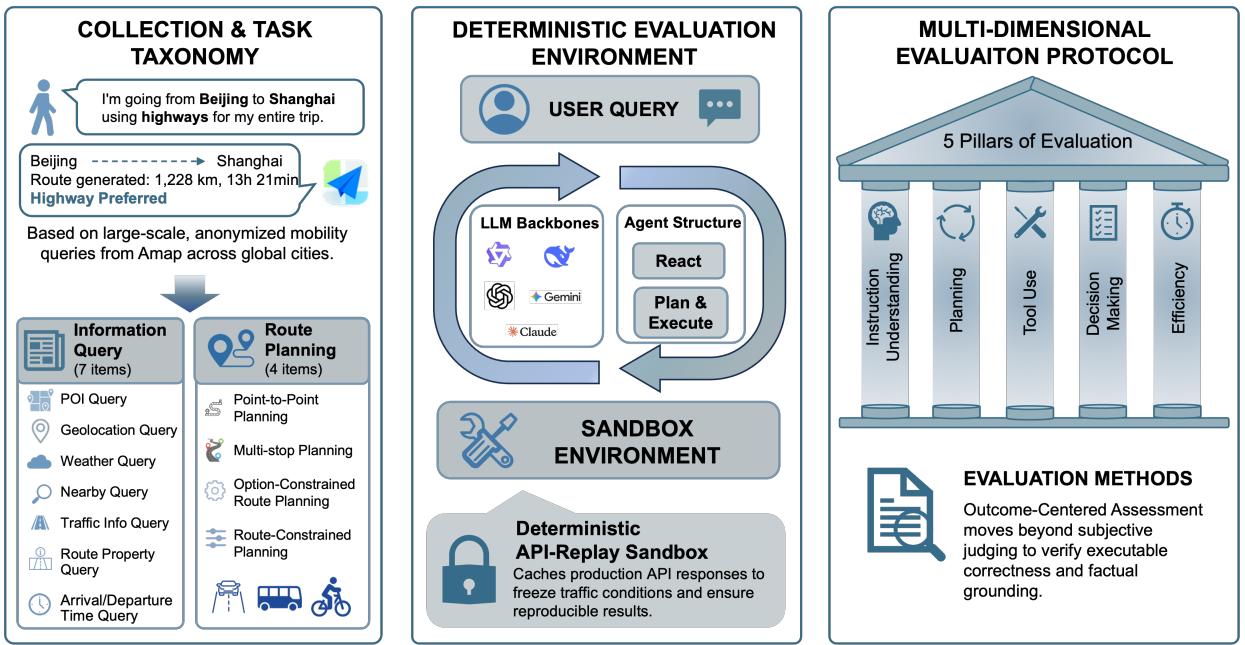
LLM 驱动的路线规划 Agent 是一个极具应用前景的方向,但系统性评估一直受限于三个难题:路线需求多样、地图服务不确定性、可复现性差。现有基准(TravelBench、TravelPlanner)聚焦于高层旅程规划,而非真实世界的逐段路线规划。
MobilityBench 直接从高德地图的大规模匿名真实用户查询构建,覆盖全球多个城市。其核心创新是确定性 API-replay 沙箱——记录并回放真实地图 API 响应,消除了实时服务带来的环境方差,确保完全可复现。评估协议以结果有效性为核心,辅以指令理解、规划能力、工具使用和效率等多维度指标。
测试发现,当前模型在基础信息检索和路线规划上表现尚可,但在偏好约束路线规划(如避开高速、最少换乘、时间敏感等)上表现显著落后——个性化出行仍有很大改善空间。数据集、评估工具已开源。
OmniGAIA: 360 任务评估全模态 Agent,OmniAtlas 展示工具推理新范式

人类智能天然融合视觉、听觉和语言的全模态感知。但当前多模态 LLM 研究主要局限于双模态交互(视觉-语言或音频-语言),既有基准也大多是双模态且以感知为主,无法衡量跨模态多跳推理和多轮工具使用。
OmniGAIA 构建了一个覆盖 9 个真实领域的 360 任务基准,涵盖视频+音频和图像+音频场景。其任务生成管线基于全模态事件图:先从原始媒体中挖掘细粒度信号,构建跨模态实体/事件图,再通过跨模态检索和外部工具扩展图,最后模糊化关键节点生成多跳 QA 任务。配套的 OmniAtlas Agent 采用工具集成推理(TIR)范式,具备主动全模态感知能力,训练使用事后引导树探索合成轨迹 + OmniDPO 做细粒度纠错。
CapImagine: 因果分析证明潜空间推理「名存实亡」,文本想象反而更强
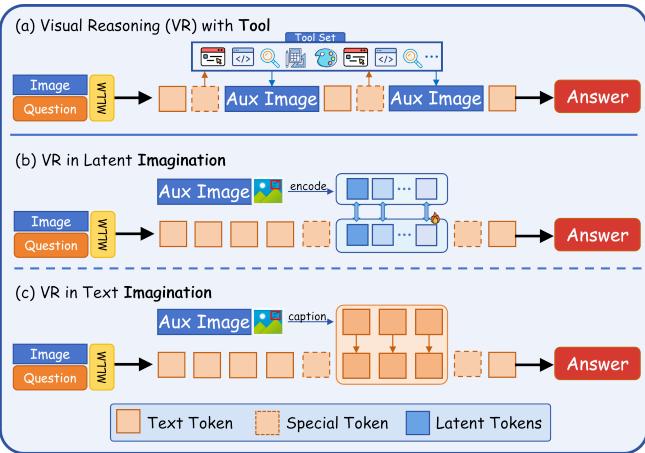
潜空间视觉推理(Latent Visual Reasoning, LVR)是一个近期很受关注的范式——让多模态 LLM 在隐藏状态空间中进行「想象」式推理。尽管结果看起来不错,但潜变量到底在做什么?模型真的在潜空间中进行了深思熟虑的推理吗?
这篇论文用因果中介分析(Causal Mediation Analysis)给出了令人震惊的答案:没有。分析发现两个关键断裂:第一,输入-潜变量断裂——对输入施加剧烈扰动,潜变量几乎不变(余弦相似度极高),说明潜变量没有有效关注输入;第二,潜变量-答案断裂——对潜变量施加扰动,最终答案几乎不受影响,说明潜变量对输出的因果效应有限。探针分析进一步显示,潜变量只编码了有限的视觉信息且彼此高度相似。
基于这一发现,论文提出了 CapImagine——教模型用文本显式描述想象内容,而非在不透明的潜空间中操作。结果极其简洁有力:CapImagine 在视觉中心基准上显著超越了复杂的潜空间基线,从根本上质疑了潜空间推理的必要性。