📋 速览目录 · 全部 31 篇
| # | 论文 | 领域 | Votes | 一句话 |
|---|---|---|---|---|
| 1 | HyTRec | 推荐系统 | 49 | 混合时序注意力处理万级行为序列,Hit Rate 提升 8%+ |
| 2 | MolHIT | AI4Science | 49 | 层级离散扩散模型首次在图扩散中实现近完美分子有效性 |
| 3 | SkyReels-V4 | 视频生成 | 38 | 1080p/32FPS/15s 音视频联合生成/修复/编辑一步到位 |
| 4 | DreamID-Omni | 视频生成 | 33 | 对称条件 DiT 实现多人身份-音色解耦,超越 Veo3/Sora2 |
| 5 | ARLArena | Agent RL | 20 | 4 维度分解 Agent RL 崩溃根因,SAMPO 稳定训练 |
| 6 | Solaris | 世界模型 | 19 | 1264 万帧 Minecraft 多人视角世界模型,全开源 |
| 7 | DualPath | LLM 推理 | 16 | 双路径 KV-Cache 加载,推理吞吐提升近 2 倍 |
| 8 | GUI-Libra | GUI Agent | 12 | 动作感知 SFT + 部分可验证 RL,AndroidWorld +15.6% |
| 9 | Sphere Encoder | 图像生成 | 11 | 球面编码单步生成媲美多步扩散,推理成本极低 |
| 10 | JavisDiT++ | 视频生成 | 10 | 仅 1M 公开数据的统一音视频生成框架,全开源 |
| 11 | VecGlypher | 字形生成 | 9 | 语言模型统一矢量字形生成 |
| 12 | World Guidance | 世界模型 | 7 | 条件空间中的世界建模引导动作生成 |
| 13 | Statics to Dynamics | 图像编辑 | 6 | 物理感知图像编辑的潜在转移先验 |
| 14 | Hepato-LLaVA | 医学 AI | 5 | 稀疏拓扑注意力的肝癌多模态大模型 |
| 15 | NanoKnow | LLM 分析 | 4 | 探测语言模型的知识边界 |
| 16 | SeaCache | 扩散加速 | 4 | 频谱演化感知缓存加速扩散模型 |
| 17 | Tri-Modal Masked Diffusion | 多模态 | 3 | 三模态掩码扩散模型的设计空间 |
| 18 | Dropping Anchor | 3D 视觉 | 3 | 球谐函数做稀疏视角高斯泼溅 |
| 19 | MCP Tool Descriptions | Agent | 2 | MCP 工具描述有异味!改善 AI Agent 工具使用 |
| 20 | UniVBench | 视频评测 | 2 | 统一视频基础模型评测 |
| 21 | Revisiting Text Ranking | 信息检索 | 2 | 重新审视深度研究中的文本排序 |
| 22 | — | — | — | — |
| 23 | — | — | — | — |
| 24 | — | — | — | — |
| 25 | — | — | — | — |
| 26 | — | — | — | — |
| 27 | — | — | — | — |
| 28 | — | — | — | — |
| 29 | — | — | — | — |
| 30 | — | — | — | — |
| 31 | — | — | — | — |
今天最显著的信号:音视频联合生成赛道集中爆发。SkyReels-V4(1080p/32FPS/15s + 同步音频)、DreamID-Omni(多人身份-音色解耦)、JavisDiT++(仅 1M 数据超越先前方法)三篇同日出现,说明视频生成正在从"画面"进化到"视听一体"。另一条主线是 Agent 系统的工程成熟度在加速:ARLArena 拆解了 Agent RL 训练崩溃的根因并给出 SAMPO 稳定训练方案,DualPath 则从推理基础设施层面把 KV-Cache 加载吞吐提升了近 2 倍。
Insight:当三篇独立团队不约而同做音视频联合生成时,说明这不是偶然——统一多模态生成正在从 Demo 走向工程化竞争,下一个战场大概率是实时交互式视听内容创作。
HyTRec: 混合时序注意力架构,万级行为序列推荐又快又准
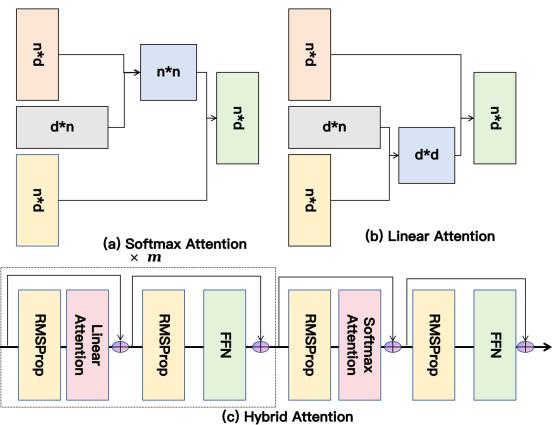
推荐系统的历史行为序列越来越长——用户在电商、内容平台上积累的点击、购买记录动辄上万条。传统 Softmax 注意力在序列长度上是 O(n²) 复杂度,处理万级序列时计算代价极高;而单纯用线性注意力虽然速度快,但对近期交互的精确建模能力不足,容易错失短期兴趣的动态变化。
HyTRec 提出了一个双通路设计:线性注意力专门处理长期稳定偏好(万级历史中"这个用户总体偏好什么"),Softmax 注意力专注捕捉近期交互信号("最近这几天他看了什么")。两条通路的输出通过可学习融合机制聚合,最终形成丰富的用户表示。此外,论文还引入了 TADN(Temporal-Aware Delta Network),对近期交互信号自动施加时效性权重——越新的行为贡献越大,但并非简单的线性衰减,而是由网络自适应学习的非线性时序权重。
在多个公开基准上,HyTRec 对超长行为序列的 Hit Rate 提升超过 8%,同时推理速度维持线性复杂度。这对于实际生产系统意义重大——不需要截断用户历史,就能在可接受延迟内完成推荐。工业界合作(得物)也意味着该方案经过了真实用户规模的验证。
MolHIT: 层级离散扩散模型,首次在图扩散中实现近完美分子有效性
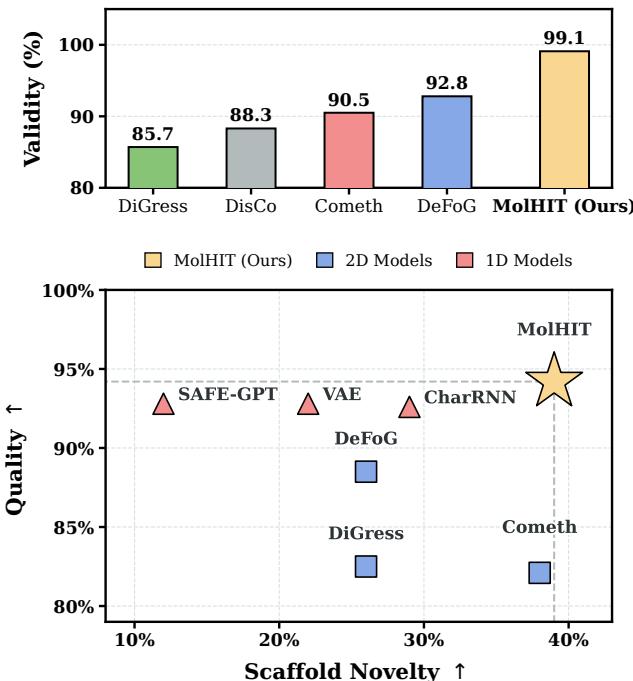
分子生成是 AI for Science 的核心任务之一。现有图扩散方法面临一个顽疾:生成的分子结构很容易违反化学键的价态规则,导致有效性(validity)远低于基于 SMILES 字符串的 1D 方法。为什么图扩散的有效性这么难提升?根本原因在于:图扩散在节点和边上的噪声添加完全独立,没有任何化学约束,去噪过程中很容易产生化学上不合法的原子-键组合。
MolHIT 提出了两个关键设计:解耦原子编码——将原子类型和化合价分开建模,让模型学习到「碳原子最多 4 个键」这类化学先验;化学先验作为额外离散类别——在离散扩散的类别空间中加入化学先验约束,引导去噪轨迹始终在合法化学结构附近运动。层级扩散则从粗到细地生成分子:先确定环状骨架,再填充官能团细节。
在 MOSES 基准上,MolHIT 不仅是图扩散方法中首次达到接近 100% 有效性,综合性能还超越了 1D 字符串方法(如 SMILES VAE)——这意味着图扩散不再需要在有效性上妥协来换取结构多样性。对于药物发现和材料科学领域,这是一个重要的里程碑。
SkyReels-V4: 双流 MMDiT 统一视频+音频的生成/修复/编辑,1080p 电影级视听一步到位
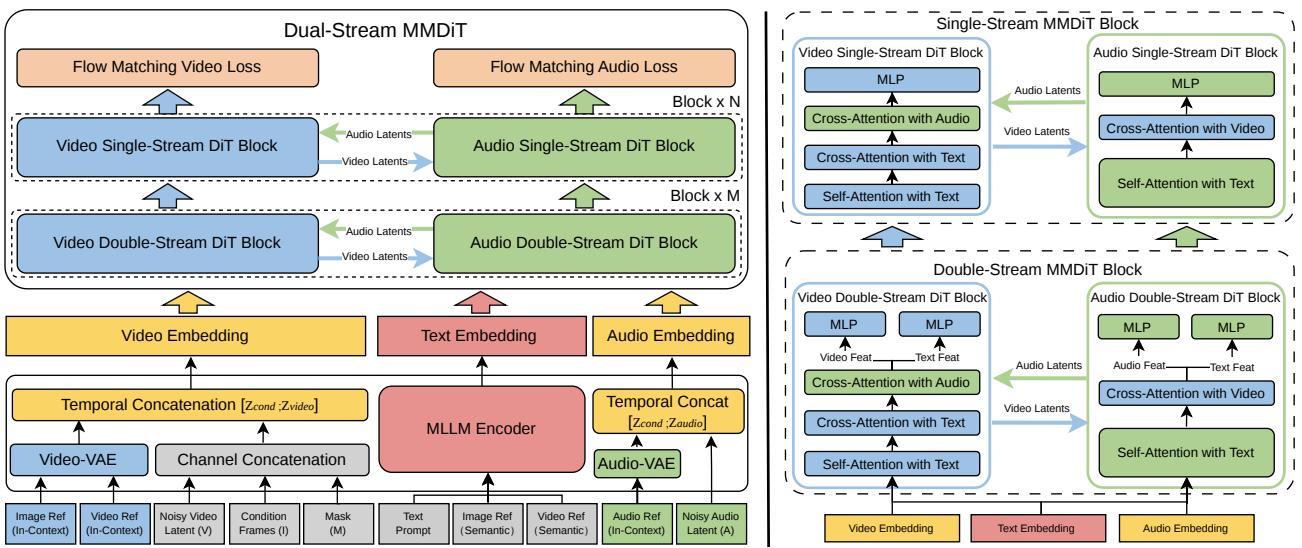
视频生成模型已经能生成高质量画面,但声音呢?现有的视频生成模型绝大多数输出的是"哑巴视频"——需要单独跑一个音频生成模型,再做音视频对齐。这种两阶段方案存在根本性问题:画面和声音在时间轴上无法保证精确同步,且两个模型的语义理解往往不一致(视频里出现的动作和对应的声音效果难以完美匹配)。
SkyReels-V4 提出了双流 MMDiT(Multi-Modal Diffusion Transformer)架构:视频流和音频流作为两个独立的 Transformer 分支,但共享同一个多模态大语言模型(MLLM)作为文本编码器。两个分支在每个 Transformer 层通过跨流注意力互相感知对方的生成状态,确保画面和声音在语义层面完全对齐。在训练框架上,所有任务(文本生成视频、视频修复、视频编辑)被统一为 inpainting 风格——将要生成/修复的部分设为"空白遮罩",已知内容作为条件,极大简化了多任务训练的复杂度。
在效率上,SkyReels-V4 采用低分辨率全序列生成 + 高分辨率关键帧细化的两阶段流程,在保证质量的同时显著降低计算成本。1080p、32FPS、15 秒的视听内容,完全通过一次模型推理完成生成——这在开源社区中尚属首次达到这一规格。
DreamID-Omni: 对称条件 DiT + 双层解耦,多人身份-音色不再张冠李戴
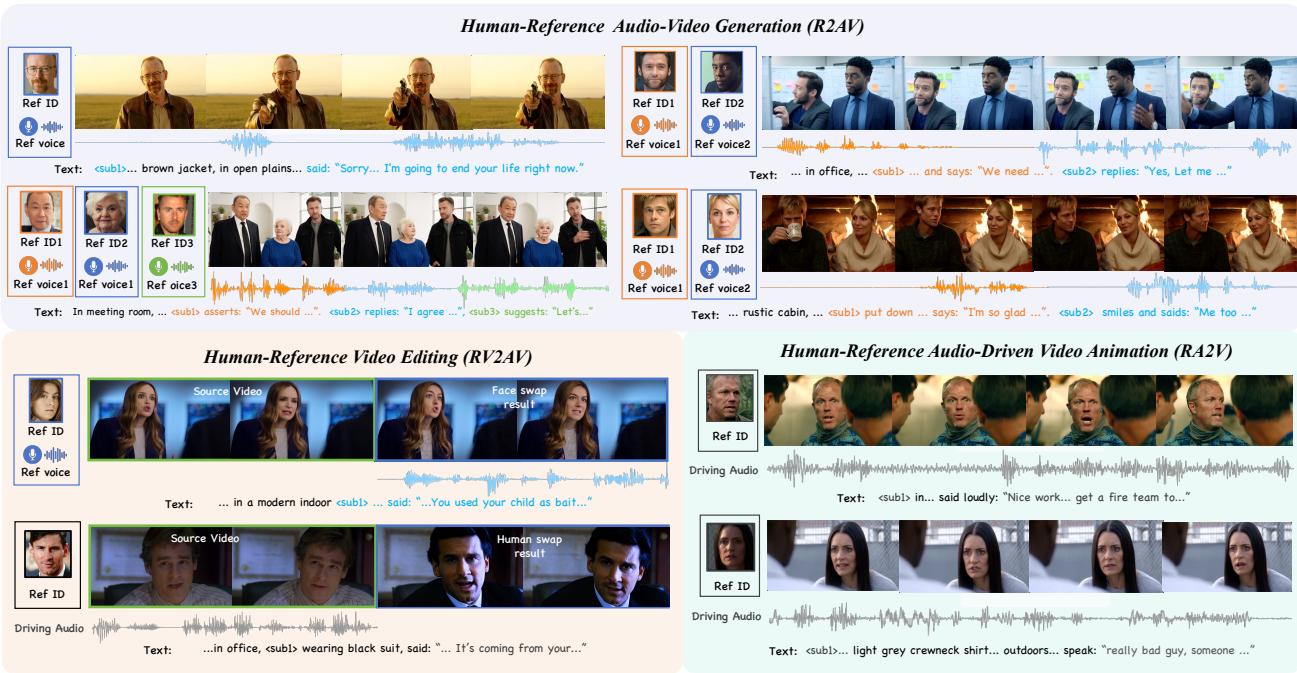
想象这样一个场景:你想生成一段视频,里面有三个人物,每个人有自己的声音和外貌。现有的音视频生成模型在单人场景下勉强可用,但到了多人场景几乎全军覆没——不同人的声音会窜台,或者某个人的脸型会影响另一个人的声音特征,身份和音色的边界极度混乱。
DreamID-Omni 从根本上重新设计了架构来解决这个问题。核心是对称条件 DiT(Symmetric Conditional DiT):视频分支和音频分支以完全对称的方式互相提供条件信息,而非一方主导另一方跟随。在解耦机制上,论文提出双层解耦(Dual-Level Disentanglement):信号层通过同步 RoPE(Rotary Position Embedding)对齐视频帧和音频帧的时序位置,确保帧级同步;语义层通过结构化描述(Structured Captions)为每个人物独立标注身份-音色对应关系,防止语义层面的跨人混淆。
通过多任务渐进式训练(Multi-Task Progressive Training),模型先在单人场景上学习基础身份-音色绑定,再逐步扩展到多人场景。最终评测中,DreamID-Omni 在音视频一致性指标上全面 SOTA,且明确超越了 Veo3 和 Sora2 等商业模型——这对于开源社区来说是一个重要的里程碑。
ARLArena: 把 Agent RL 训练崩溃拆成四个维度逐个击破,SAMPO 让训练不再靠运气
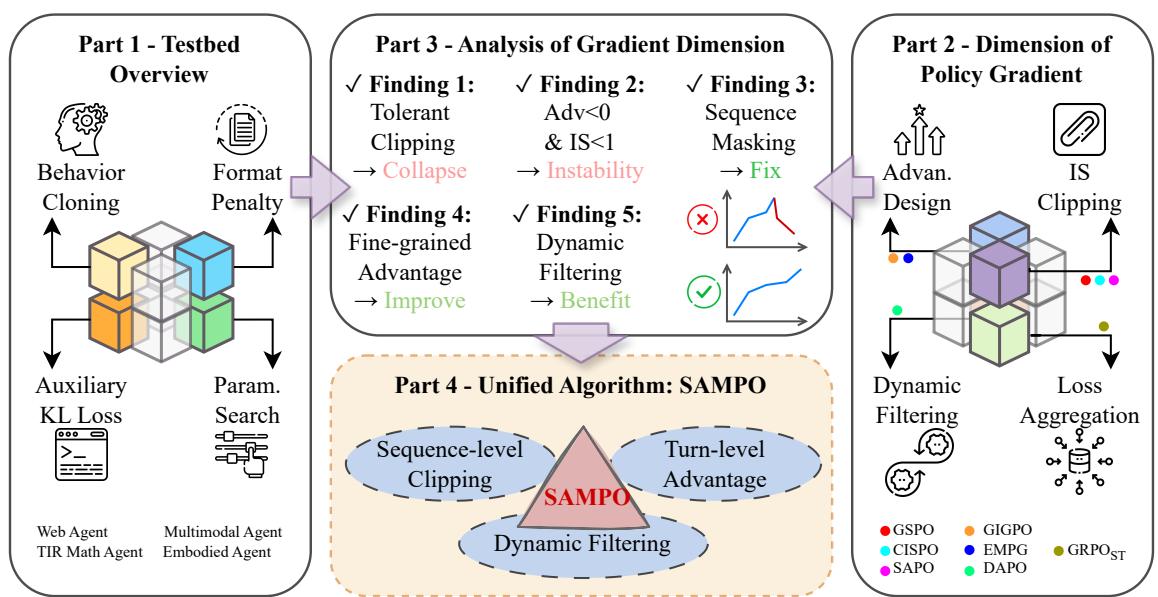
用强化学习训练 LLM Agent 是当前最热门的方向之一,但从业者都知道一个令人沮丧的现象:Agent RL 训练极不稳定。不同超参数、不同随机种子、甚至不同的任务描述措辞,都可能让训练要么发散、要么陷入奖励坍缩(reward hacking)。大量工程时间被花费在"为什么这次训练崩了"这个问题上,缺乏系统性的诊断框架。
ARLArena 的出发点是:先构建一个干净的标准化测试床,再系统拆解训练崩溃的根因。研究团队将策略梯度分解为 4 个核心维度:(1)优势估计——组内归一化 vs 跨轨迹归一化的影响;(2)KL 正则化——惩罚力度与探索效率的权衡;(3)熵控制——防止策略过早确定性坍缩;(4)奖励塑形——稀疏奖励 vs 中间奖励的训练动态差异。通过系统消融,他们发现大多数崩溃案例可以归因到这 4 个维度中的 1-2 个失调。
基于系统分析,团队蒸馏出 SAMPO(Stable Agentic Policy Optimization)方法,将 4 个维度的最优实践整合为一套统一的训练配方。在 ALFWorld、Sokoban 等代表性 Agent 任务上,SAMPO 在多个随机种子下展现出一致稳定的训练曲线——这在以往是极难实现的。