GPT-5.4 发布深度解读:OpenAI 把模型竞争推向专业工作流时代
GPT-5.4
OpenAI
Agent
企业软件
一句话判断
GPT-5.4 的意义,不只是又一轮 benchmark 提升,而是 OpenAI 首次把 推理、编码、工具调用、搜索与原生电脑操作真正拉进同一条主线模型。
模型竞争的焦点,正在从“谁更会回答”,转向“谁更能在真实软件、文档、表格和浏览器里稳定交付结果”。

OpenAI GPT-5.4 Thinking 官方配图。用于本次发布页面与配套发布素材。
一、TL;DR:这次升级到底升级了什么
关键结论
- 知识工作能力抬升。OpenAI 给出的 GDPval 成绩从 GPT-5.2 的 70.9% 提升到 83.0%,面向初级投行分析师的表格建模测试从 68.4% 提升到 87.3%。
- 电脑操作首次成主线卖点。GPT-5.4 在 OSWorld-Verified 上达到 75.0%,超过 OpenAI 披露的人类表现 72.4%,明显高于 GPT-5.2 的 47.3%。
- Agent 成本结构开始改善。API 新增的
tool search在 MCP Atlas 的 250 个任务中,把 token 使用量降低 47%,同时保持相同准确率。 - 不是简单的“全项碾压”。GPT-5.4 Pro 在浏览与金融代理场景更强,但标准版 GPT-5.4 在 GDPval 和内部投行建模任务上反而更高。
83.0%
GDPval
87.3%
投行建模
75.0%
OSWorld
-47%
tool search token
OpenAI 在 2026 年 3 月 5 日同步发布了 GPT-5.4 Thinking、API 模型 gpt-5.4 与 gpt-5.4-pro,并将 GPT-5.3-Codex 的前沿编码能力并入 GPT-5.4 主线模型。对开发者、产品经理、投研和企业 IT 而言,这意味着一个更清晰的方向:未来高价值 AI,不是一个更会聊天的模型,而是一个更会把活做完的系统。
为什么值得关注
从官方发布措辞到 benchmark 设计都能看出,OpenAI 正在把评价体系从“答对多少题”切换到“能不能完成表格、PPT、搜索、工具调用和桌面操作等真实流程”。这比再涨几分考试分数更重要。
二、博客原图:OpenAI 最想让外界看到什么
从发布页可直接提取的静态原图里,最核心的是这张知识工作对比图。它不是在讲“模型会写更多字”,而是在讲 模型能把表格工作做得更像一个初级分析师。这也是 GPT-5.4 发布叙事的中心变化。
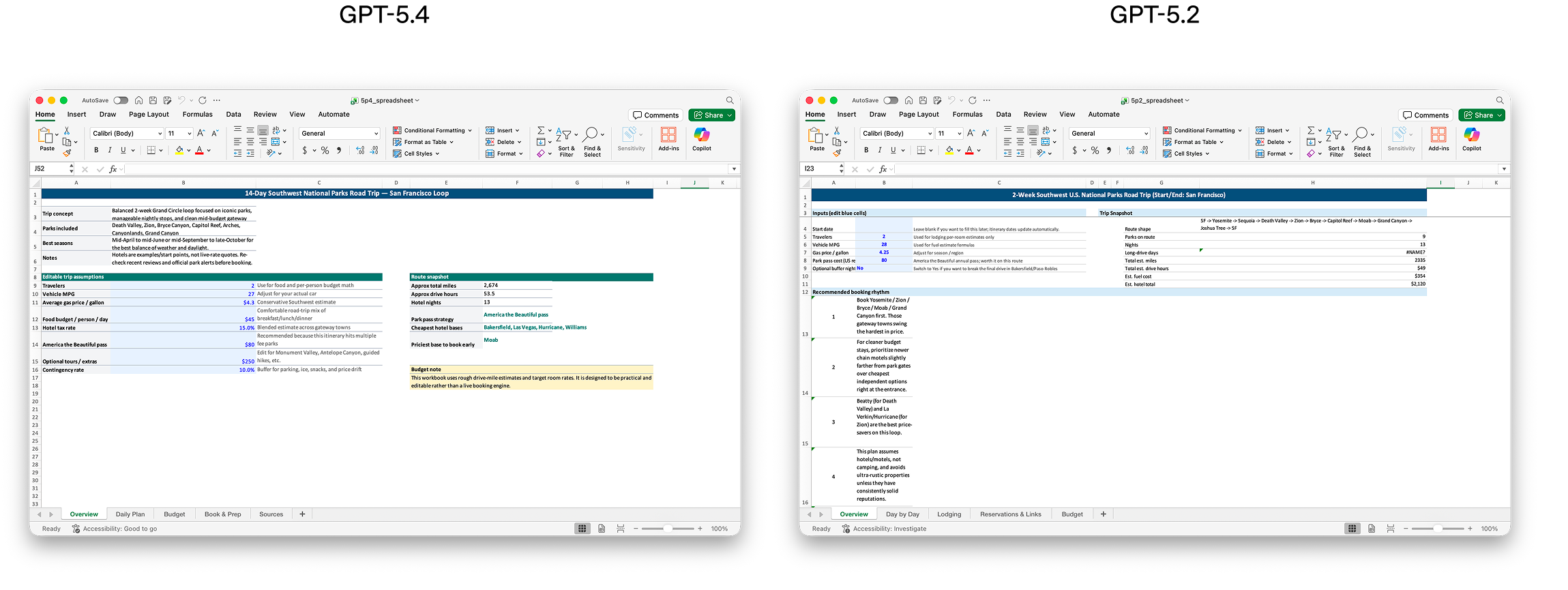
OpenAI 博客正文原图:Spreadsheet 对比图。官方用它来展示 GPT-5.4 与 GPT-5.2 在知识工作输出质量上的差异。
这张图配合官方披露的内部评测数据,形成了非常完整的产品叙事闭环:知识工作是最容易付费、也最容易衡量 ROI 的 AI 场景之一。OpenAI 把它放在发布页前半段,说明 GPT-5.4 的核心目标用户并不是“刷榜观众”,而是需要实际产出的专业工作者。
图片说明
GPT-5.4 发布页中,除上述静态原图外,还有多段搜索、电脑操作和游戏环境演示视频。本文保留了可直接引用的官方静态原图,并将视频部分以文字方式整理。