GPT-5.5 — 完全重训练 · OpenAI 转型推理公司
一句话定位
不是 GPT-5.4 的微调版,而是自 GPT-4.5 以来首次完全重新预训练的基础模型。
代号 Spud,GPT-5.5 融合了 GPT 系列的生成能力与 o1 的结构化推理框架,于 2026 年 3 月 24 日完成预训练,是 OpenAI 进入 AGI 冲刺阶段前最后一次大规模基础模型重构[1]。
- 代号 Spud,融合 GPT 生成能力与 o1 结构化推理[1]
- Sam Altman:"OpenAI 必须在相当程度上成为一家 AI 推理公司"(发布直播引语)[3]
- 预训练于 2026 年 3 月 24 日完成[4]
- NVIDIA GB200 NVL72 10 万卡集群支撑训练[7]
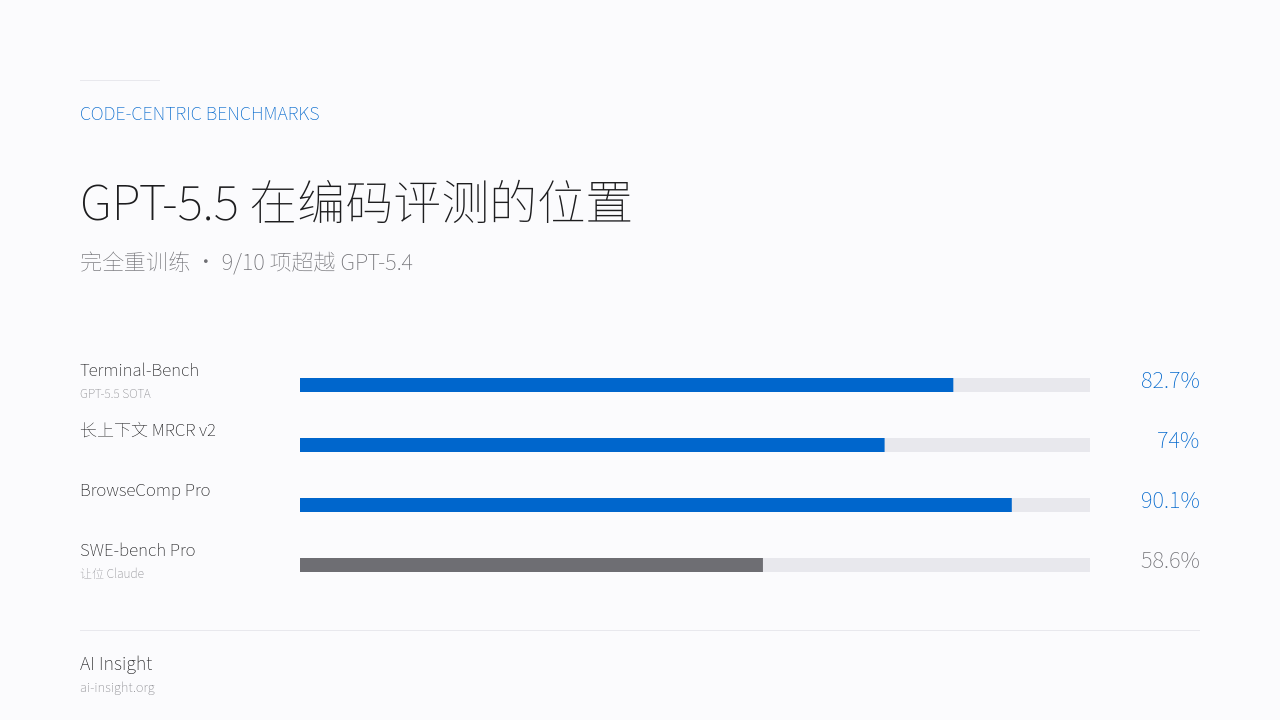
Benchmark · 9/10 超越 GPT-5.4
长上下文跳跃 37pp,Terminal-Bench SOTA。
| 评测项 | GPT-5.5 | GPT-5.4 | 变化 |
|---|---|---|---|
| Terminal-Bench | 82.7% | 75.1% | +7.6pp |
| ARC-AGI-2 | — | — | +11.7pp |
| MCP Atlas | — | — | +8.1pp |
| 长上下文召回(MRCR v2) | 74.0% | 36.6% | +37.4pp |
| GDPval | 84.9% | — | — |
| 事实准确率(System Card) | +23% | 基准 | 声明级,子集测试 |
| Token 效率(官方) | 显著减少 | 基准 | 未给精确比例 |
竞品对比
与同期旗舰横向对比。
| 评测项 | GPT-5.5 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|
| Terminal-Bench | 82.7 | 69.4 | 68.5 |
| SWE-Bench Pro | 58.6 | 64.3 * | — |
| BrowseComp Pro | 90.1 | — | 85.9 |
| 长上下文(MRCR v2) | 74.0 | 32.2 | — |
| 写作偏好(盲测) | 29% | 47% | 24% |
| Intelligence Index | 60 | 57 | 57 |
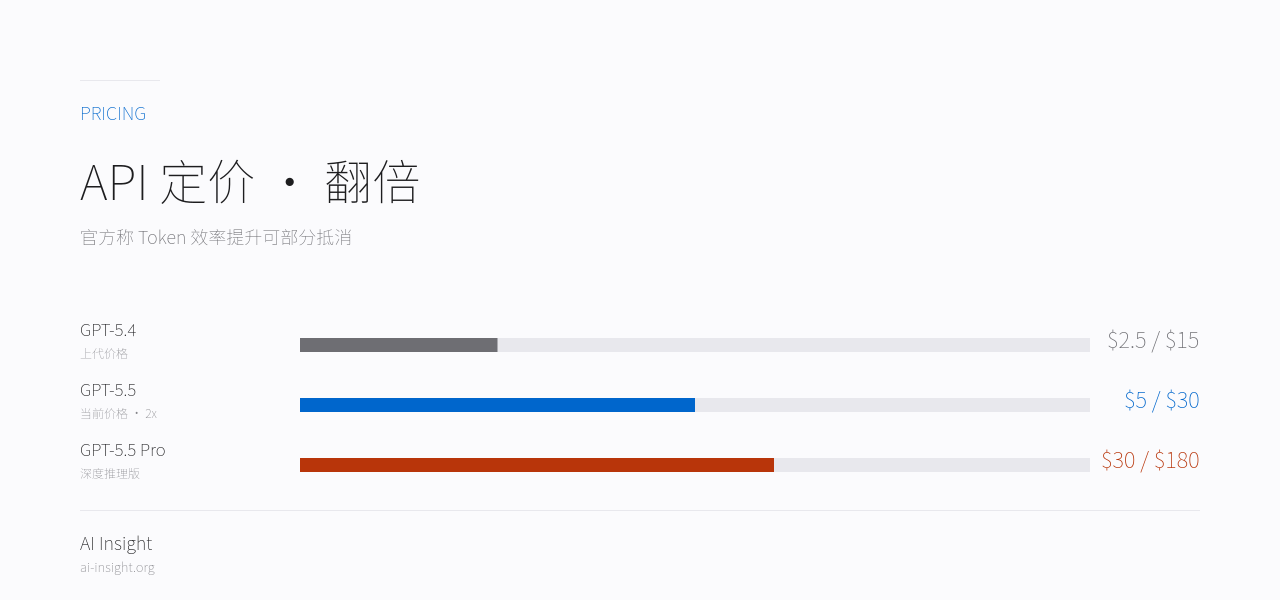
API 定价
定价翻倍,官方称 token 效率可部分对冲。
GPT-5.5 定价相比 GPT-5.4 翻倍,但官方强调 token 效率提升可部分抵消成本增量[1]。
| 模型 | 输入 /1M tokens | 输出 /1M tokens | 备注 |
|---|---|---|---|
| GPT-5.5 | $5 | $30 | GPT-5.4 的 2x |
| GPT-5.5 Pro | $30 | $180 | 深度推理版 |
| GPT-5.4(参考) | $2.5 | $15 | — |
- 上下文窗口:1M tokens
- Batch API 照常享受 50% 折扣
- Token 效率:官方称显著减少,Artificial Analysis 测算综合成本增幅约 20%
- 模型 ID:
gpt-5.5/gpt-5.5-2026-04-23
Codex 集成
GPT-5.5 是 Codex 默认推荐模型。
GPT-5.5 是 OpenAI Codex 的默认推荐模型[7][9]:
- 更擅长实现、重构、调试、测试四类核心编码任务
- 在大型系统间保持上下文连贯性的能力显著提升
- 长上下文 74% 召回率对跨文件代码审计有直接价值
- 训练集群:NVIDIA GB200 NVL72 10 万卡,OpenAI 与 NVIDIA 深度协同[7]
Altman 的表态
三句话定义转型方向。
To a significant degree, we have to become an AI inference company now.
— Sam Altman,GPT-5.5 发布会
the last major milestone before AGI
— Sam Altman,对 GPT-5.5 的定位
the completion of a specific phase of intelligence development
— Sam Altman,关于 GPT-5 系列
Altman "OpenAI 必须成为推理公司" 的表述暗示公司商业模式正在从模型授权向推理服务转型——高效服务模型、以量取胜,比继续堆参数更关键。
业界反响
学界看好,开发者抱怨定价。
Ethan Mollick(沃顿商学院)[6]:"very big deal…rapid improvement is not finished"——认为 GPT-5.5 标志着 AI 能力快速提升的势头并未放缓。
纽约银行 CIO:"impressive hallucination resistance"(抗幻觉能力印象深刻)——对金融场景合规应用具有实质价值。
开发者社区:普遍反馈模型更快更精简,倾向小范围可执行修改而非大段重写,Codex 集成体验明显改善。
主要争议:定价翻倍是核心抱怨,部分开发者表示会维持使用 GPT-5.4 或等待 Batch API 折扣窗口[8]。
怎么用
四种接入入口。
| 入口 | 说明 | 状态 |
|---|---|---|
| ChatGPT | Plus / Pro / Business / Enterprise 直接使用 | 已上线 |
| Codex | 默认推荐模型 | 已上线 |
| API | "very soon"(正式上线日期待定) | 即将 |
| 模型 ID | gpt-5.5 / gpt-5.5-2026-04-23 | — |
Editor's Take
首个完全重训练的 GPT-5 系列模型,意味着 GPT-5 的能力天花板被重新设定。此前 5.1/5.2/5.3/5.4 的迭代均基于同一基础模型进行微调,而 5.5 从预训练起点开始,释放的信号是 OpenAI 认为有足够新数据和架构改进值得重新训练。
长上下文 37pp 的跳跃(36.6%→74.0%)是这次发布最被低估的数字。对企业级应用(合同逐条分析、大型代码库审计、多轮研究综述)而言,这不是锦上添花,而是从"勉强可用"到"真正可部署"的质变。
Altman "OpenAI 必须成为推理公司" 的表态,可能比任何模型参数更值得关注——它预示 OpenAI 的重心正从"做最强模型"转向"高效部署模型"。但 SWE-Bench Pro 上以 58.6% 输给 Claude Opus 4.7(64.3%,争议未解)说明真正通用的编程能力仍有差距,营销叙事与技术事实需要区分。
定价翻倍是一个市场信号:顶级推理能力不再低价竞争。对平台开发者而言,多模型路由(对话用 GPT-5.4,长上下文/复杂任务用 GPT-5.5)将成为控制成本的标配策略。
References
参考文献。
- OpenAI Blog — openai.com/index/introducing-gpt-5-5/
- System Card — deploymentsafety.openai.com/gpt-5-5
- CNBC — Sam Altman 访谈引述(发布会引语)
- The Decoder — the-decoder.com/openai-unveils-gpt-5-5
- VentureBeat — GPT-5.5 narrowly beats Anthropic(SWE-Bench Pro 争议)
- Ethan Mollick — oneusefulthing.org/p/sign-of-the-future-gpt-55
- NVIDIA Blog — blogs.nvidia.com/blog/openai-codex-gpt-5-5-ai-agents/
- LLM Stats — llm-stats.com/blog/research/gpt-5-5-vs-gpt-5-4
- 9to5Mac — Codex + ChatGPT 集成报道
- Artificial Analysis — artificialanalysis.ai(Intelligence Index · 写作偏好盲测)